
ETL pipelines are data processing systems that transform businesses into intelligent, semi-autonomous creatures. This article dives into their core, and shows you how to implement them into your company.
The most common use case for an ETL pipeline is extracting data from a database and moving it into a different database or file system location. There are many reasons why you would want to do this, but the most common reason is that your current database may not have enough capacity or you need more storage space for your files.
But that’s not all.
The automation of an ETL pipeline solves many more problems such as producing a constant stream of refined feedback and insight, that’s ready to use.
Let’s dig a little deeper.
What are ETL Pipelines?
ETL pipelines consist of a set of tools and processes for data migration, transformation, loading, and cleansing. It is used to extract the data from one source system into another target system.
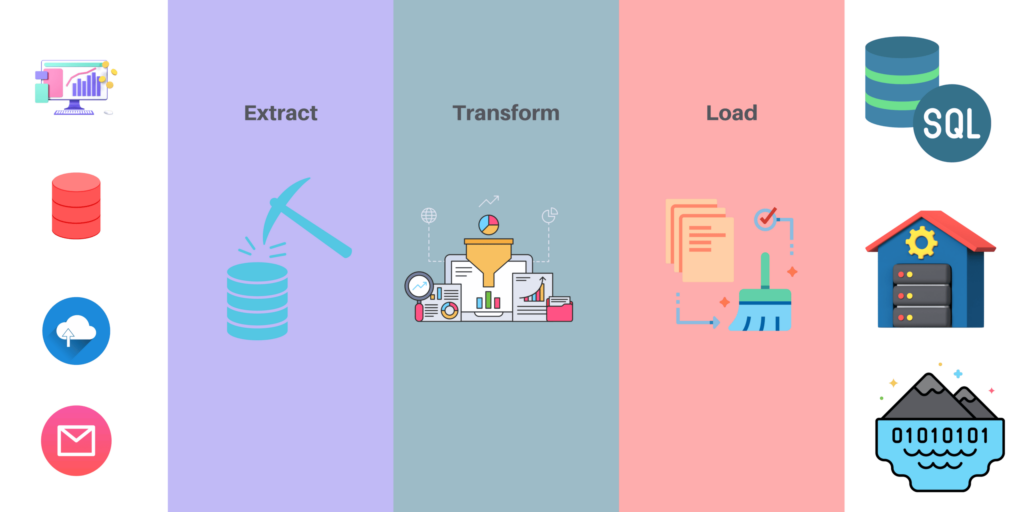
The ETL pipeline can be divided into three main components: Source System, Transformation, and Loader.
Source System is the place where the raw data comes from. This could be an existing database or files on disk etc. It contains all data that needs to be processed. It can be a relational database, an Excel spreadsheet, or any other type of data source.
Transformation is a process that transforms raw data in order to make it more usable by other systems like databases, web services, or applications that are not natively supported by the source system. In other words, this component transforms the raw data from your source into a format that makes sense for your application logic. For example, if you are processing sales figures and you want to calculate total revenue for each month, then this step would transform the raw data into monthly totals.
Loader is a tool that loads transformed data into a destination system such as SQL Server or Oracle Databas so that it can be processed further by other systems like reporting and business intelligence tools.
Additionally, there are other steps within these core processes.
Load Transformations
These transformations take place after every transformation in order to make sure that no errors occur during processing and also provide better performance when dealing with large volumes of data. You can use them to load all necessary information from one table into another (e.g., loading historical records from one table into another).
Load Operations
These operations can perform daily updates on different tables within your database (e.g., updating product prices). They might include things such as inserting new rows in existing products tables based on their stock levels or removing old rows based on their expiry dates etc. If we were talking about real-life applications here, these might include things like adding new customers every day based on some criteria set by our business users, deleting expired customers, etc.
Reporting Operations
It’s time for reporting after you perform all the data transformations. You could use SQL Server Reporting Services or Power BI reports in order to get instant feedback about how well your ETL has worked out so far.
What are the benefits of using ETL pipelines?
There are many benefits to automating your data pipeline. Many of them highlight the advancing efficiency within your company communications and feedback for supporting intelligent innovation.
Saves time and resources
The primary benefit of using an ETL pipeline is that you can automate the process by writing scripts to do all your transformations in one place. This makes sure that you have consistent results across all your systems, which means less time spent manually doing things like creating reports with Excel spreadsheets or manually copying files between different applications.
Imagine the time spent by your employees collecting and cleaning data is all of a sudden freed up. It means that tedious and repetitive data harvesting tasks no longer bog down your team. As a result, they are free to work on creative and managerial operations.
Reduces errors and clarifies data insights
You also get much better control over what happens to your data. If there are any errors in the transformation process you catch them before ever leaving your system. As a result, the end-points of your data – where your services or products contact customers – honor their feedback.
Eliminates redundancy
Finally, everything happens within a single script. This means you don’t need to worry about having multiple people working on the same report at once. You just write one script and let everyone run it.
How to implement ETL pipelines into your business.
A lot of companies have started to implement ETL processes in their business. The main reasons are:
- The need for data consistency and the ability to extract information from different sources into a single database or system.
- You can solve data quality issues with automated processes that analyze data and produce reports on it. This will help you improve your organization’s performance, reduce costs and increase customer satisfaction.
- The need for accurate and timely information about your customers. This will help you improve customer service, reduce costs and increase customer satisfaction. Data accuracy is one of the most important factors that determine how effective your business will be in the future.
But how do you get the data refinery that is an ETL pipeline into operation?
You can start small by harvesting data sets from social media platforms like Facebook or Reddit, and review websites like Yelp.
Internally, you can collect key data from emails and use that information to identify gaps in services and products. From here, you can make a priority list to deal with.
On a larger scale, it’s possible to feed your business with data from across the internet automatically. You can then organize it into readable formats like PDFs, Excel Worksheets, or CVS files.
You can read more about where to find data in our Comprehensive Guide to Datasets. But for now, let’s show you the gist of data collection with automated software scripts called web scrapers.
Automating ETL pipelines with web scraping tools.
Automating your ETL pipeline with web scraping tools is a process that allows you to automate all the steps of your data processing pipeline.
- Data collection via web crawling and web scraping
- Data cleansing, such as removing duplicates or bad records from your dataset
- Parsing and cleaning text files
- Loading CSV files into databases
- Data Visualization, such as creating bar charts and graphs
You can perform all of these steps manually, using separate tools — but that requires a lot of learning and has the potential for many errors if you don’t know what you’re doing.
There are services available that you can discover in our research of scraping tools that do most of this process for you.
If you decide to use these streamlined services, we recommend pairing them with rotating residential proxies. In short, they can speed up the data processing, expand your reach on the internet, keep you safe from data vulnerabilities, and bypass IP bans.


