Los ETL pipelines son sistemas de procesamiento de datos que transforman las empresas en criaturas inteligentes y semiautónomas. Este artículo se sumerge en su esencia y te muestra cómo implantarlos en tu empresa.
El caso de uso más común para una canalización ETL es extraer datos de una base de datos y moverlos a otra base de datos o ubicación del sistema de archivos. Hay muchas razones para hacerlo, pero la más habitual es que la base de datos actual no tenga capacidad suficiente o que se necesite más espacio de almacenamiento para los archivos.
Pero eso no es todo.
La automatización de una canalización ETL resuelve muchos más problemas, como la producción de un flujo constante de información y conocimientos refinados, listos para su uso.
Profundicemos un poco más.
¿Qué son los ETL Pipelines?
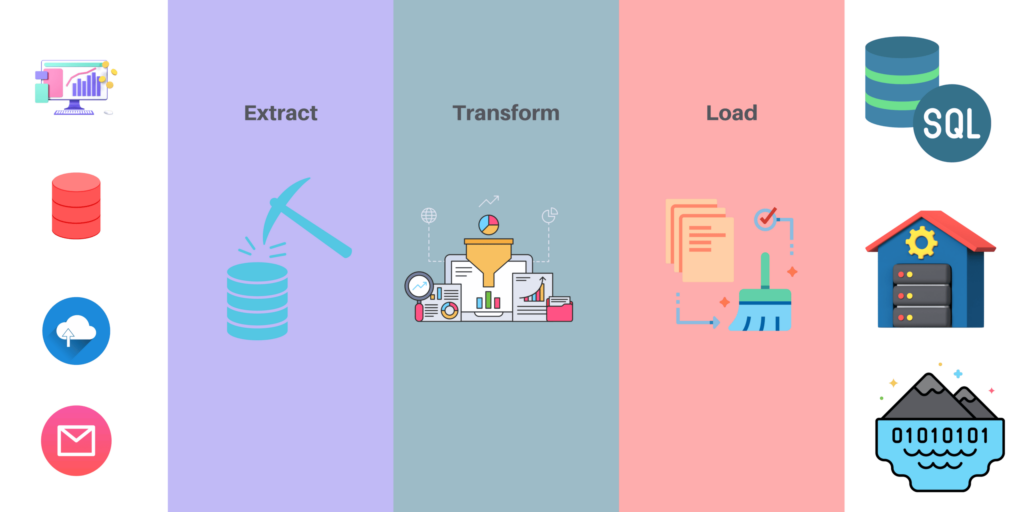
Las canalizaciones ETL consisten en un conjunto de herramientas y procesos para la migración, transformación, carga y limpieza de datos. Se utiliza para extraer los datos de un sistema de origen a otro de destino.
El canal ETL puede dividirse en tres componentes principales: Sistema fuente, Transformación y Cargador.
Source System is the place where the raw data comes from. This could be an existing database or files on disk etc. It contains all data that needs to be processed. It can be a relational database, an Excel spreadsheet, or any other type of data source.
Transformation is a process that transforms raw data in order to make it more usable by other systems like databases, web services, or applications that are not natively supported by the source system. In other words, this component transforms the raw data from your source into a format that makes sense for your application logic. For example, if you are processing sales figures and you want to calculate total revenue for each month, then this step would transform the raw data into monthly totals.
Loader is a tool that loads transformed data into a destination system such as SQL Server or Oracle Databas so that it can be processed further by other systems like reporting and business intelligence tools.
Además, hay otros pasos dentro de estos procesos básicos.
Transformaciones de carga
Estas transformaciones tienen lugar después de cada transformación para asegurarse de que no se producen errores durante el procesamiento y también proporcionan un mejor rendimiento cuando se trata de grandes volúmenes de datos. Puedes utilizarlas para cargar toda la información necesaria de una tabla a otra (por ejemplo, cargar registros históricos de una tabla a otra).
Operaciones de carga
Estas operaciones pueden realizar actualizaciones diarias en diferentes tablas de su base de datos (por ejemplo, actualizar los precios de los productos). Pueden incluir cosas como la inserción de nuevas filas en las tablas de productos existentes en función de sus niveles de existencias o la eliminación de filas antiguas en función de sus fechas de caducidad, etc. Si estuviéramos hablando de aplicaciones de la vida real, podrían incluir cosas como añadir nuevos clientes cada día en función de algunos criterios establecidos por nuestros usuarios empresariales, eliminar clientes caducados, etc.
Operaciones de información
Una vez realizadas todas las transformaciones de datos, es hora de elaborar informes. Puede utilizar SQL Server Reporting Services o los informes de Power BI para obtener información instantánea sobre lo bien que ha funcionado su ETL hasta el momento.
¿Cuáles son las ventajas de utilizar ETL pipelines?
La automatización del flujo de datos tiene muchas ventajas. Muchas de ellas destacan el avance de la eficiencia en las comunicaciones de su empresa y la retroalimentación para apoyar la innovación inteligente.
Ahorra tiempo y recursos
La principal ventaja de utilizar una canalización ETL es que puede automatizar el proceso escribiendo secuencias de comandos para realizar todas las transformaciones en un único lugar. De este modo se garantiza la coherencia de los resultados en todos los sistemas, lo que se traduce en menos tiempo dedicado a tareas manuales como la creación de informes con hojas de cálculo Excel o la copia manual de archivos entre distintas aplicaciones.
Imagine que el tiempo que sus empleados dedican a recopilar y limpiar datos se libera de repente. Esto significa que las tediosas y repetitivas tareas de recopilación de datos ya no agobian a su equipo. De este modo, pueden dedicarse a operaciones creativas y de gestión.
Reduce los errores y aclara los datos
También se controla mucho mejor lo que ocurre con los datos. Si hay algún error en el proceso de transformación, usted lo detecta antes de que salga de su sistema. Como resultado, los puntos finales de sus datos -donde sus servicios o productos entran en contacto con los clientes- respetan sus opiniones.
Elimina la redundancia
Por último, todo ocurre dentro de un único script. Esto significa que no tienes que preocuparte de tener a varias personas trabajando en el mismo informe a la vez. Sólo tienes que escribir un script y dejar que todos lo ejecuten.
Cómo implantar canalizaciones ETL en su empresa.
Muchas empresas han empezado a implantar procesos ETL en su negocio. Las principales razones son:
- La necesidad de coherencia de los datos y la capacidad de extraer información de distintas fuentes en una única base de datos o sistema.
- Puede resolver los problemas de calidad de los datos con procesos automatizados que analicen los datos y elaboren informes sobre ellos. Esto le ayudará a mejorar el rendimiento de su organización, reducir costes y aumentar la satisfacción del cliente.
- La necesidad de disponer de información precisa y oportuna sobre sus clientes. Esto le ayudará a mejorar el servicio al cliente, reducir costes y aumentar la satisfacción del cliente. La precisión de los datos es uno de los factores más importantes que determinan la eficacia de su empresa en el futuro.
Pero, ¿cómo se pone en marcha la refinería de datos que es una canalización ETL?
Puedes empezar por recopilar conjuntos de datos de plataformas de redes sociales como Facebook o Reddit, y de sitios web de reseñas como Yelp.
Internamente, puede recopilar datos clave de los correos electrónicos y utilizar esa información para identificar carencias en servicios y productos. A partir de aquí, puedes hacer una lista de prioridades a tratar.
A mayor escala, es posible alimentar su empresa con datos procedentes de Internet de forma automática. A continuación, puedes organizarlos en formatos legibles como PDF, hojas de cálculo de Excel o archivos CVS.
You can read more about where to find data in our Comprehensive Guide to Datasets. But for now, let’s show you the gist of data collection with automated software scripts called web scrapers.
Automatización de canalizaciones ETL con herramientas de raspado web.
Automating your ETL pipeline with web scraping tools is a process that allows you to automate all the steps of your data processing pipeline.
- Recogida de datos mediante web crawling y web scraping
- Limpieza de datos, como la eliminación de duplicados o registros erróneos del conjunto de datos
- Análisis sintáctico y limpieza de archivos de texto
- Carga de archivos CSV en bases de datos
- Visualización de datos, como la creación de diagramas de barras y gráficos
Puedes realizar todos estos pasos manualmente, utilizando herramientas independientes, pero eso requiere mucho aprendizaje y puede dar lugar a muchos errores si no sabes lo que estás haciendo.
There are services available that you can discover in our research of scraping tools that do most of this process for you.
If you decide to use these streamlined services, we recommend pairing them with rotating residential proxies. In short, they can speed up the data processing, expand your reach on the internet, keep you safe from data vulnerabilities, and bypass IP bans.