
Les pipelines ETL sont des systèmes de traitement des données qui transforment les entreprises en créatures intelligentes et semi-autonomes. Cet article se penche sur leur cœur et vous montre comment les mettre en œuvre dans votre entreprise.
Le cas d'utilisation le plus courant d'un pipeline ETL est l'extraction de données d'une base de données et leur transfert vers une autre base de données ou un autre système de fichiers. Il existe de nombreuses raisons de procéder à cette opération, mais la plus courante est que la capacité de votre base de données actuelle est insuffisante ou que vous avez besoin de plus d'espace de stockage pour vos fichiers.
Mais ce n'est pas tout.
L'automatisation d'un pipeline ETL résout bien d'autres problèmes, comme la production d'un flux constant d'informations et de connaissances affinées, prêtes à être utilisées.
Creusons un peu plus loin.
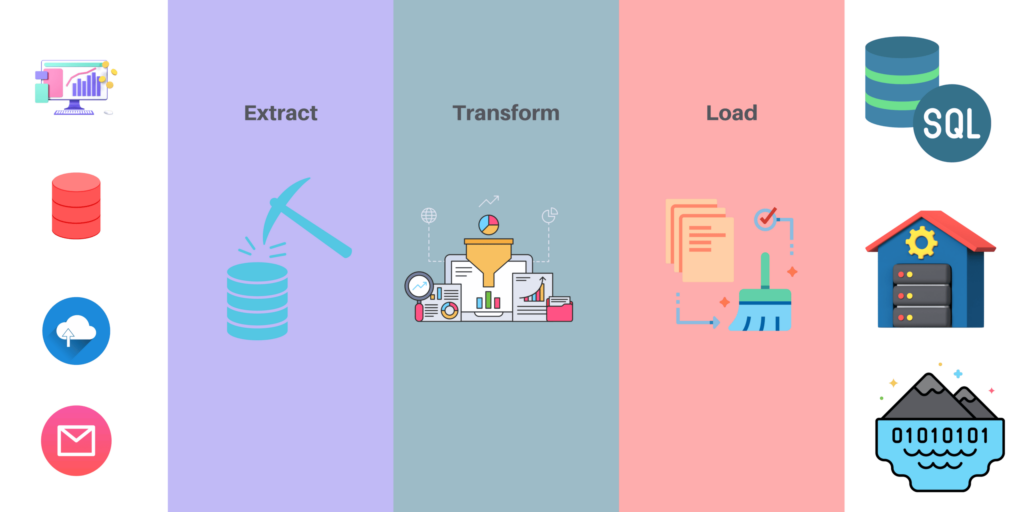
Qu'est-ce qu'un pipeline ETL ?
Les pipelines ETL consistent en un ensemble d'outils et de processus pour la migration, la transformation, le chargement et le nettoyage des données. Ils sont utilisés pour extraire les données d'un système source vers un autre système cible.
Le pipeline ETL peut être divisé en trois composants principaux : le système source, la transformation et le chargeur.
Le système sourceest l'endroit d'où proviennent les données brutes. Il peut s'agir d'une base de données existante, de fichiers stockés sur un disque, etc. Il contient toutes les données qui doivent être traitées. Il peut s'agir d'une base de données relationnelle, d'une feuille de calcul Excel ou de tout autre type de source de données.
La transformationest un processus qui transforme les données brutes afin de les rendre plus exploitables par d'autres systèmes, tels que des bases de données, des services Web ou des applications qui ne sont pas pris en charge en natif par le système source. En d'autres termes, ce composant transforme les données brutes provenant de votre source en un format adapté à la logique de votre application. Par exemple, si vous traitez des chiffres de vente et que vous souhaitez calculer le chiffre d'affaires total pour chaque mois, cette étape transformera les données brutes en totaux mensuels.
Loaderest un outil qui charge des données transformées dans un système de destination, tel que SQL Server ou Oracle Database, afin qu'elles puissent être traitées ultérieurement par d'autres systèmes, comme des outils de reporting et de veille économique.
En outre, ces processus de base comportent d'autres étapes.
Transformations de la charge
Ces transformations ont lieu après chaque transformation afin de s'assurer qu'aucune erreur ne se produit pendant le traitement et d'améliorer les performances lorsque l'on traite de grands volumes de données. Vous pouvez les utiliser pour charger toutes les informations nécessaires d'une table dans une autre (par exemple, charger des enregistrements historiques d'une table dans une autre).
Opérations de chargement
Ces opérations permettent d'effectuer des mises à jour quotidiennes sur différentes tables de votre base de données (par exemple, la mise à jour des prix des produits). Elles peuvent inclure des opérations telles que l'insertion de nouvelles lignes dans les tables de produits existantes en fonction de leur niveau de stock ou la suppression d'anciennes lignes en fonction de leur date d'expiration, etc. Si nous parlions ici d'applications réelles, il pourrait s'agir d'ajouter chaque jour de nouveaux clients sur la base de certains critères définis par nos utilisateurs professionnels, de supprimer des clients arrivés à expiration, etc.
Opérations de reporting
Après avoir effectué toutes les transformations de données, il est temps d'établir des rapports. Vous pouvez utiliser SQL Server Reporting Services ou les rapports Power BI afin d'obtenir un retour d'information instantané sur l'efficacité de votre ETL jusqu'à présent.
Quels sont les avantages de l'utilisation des pipelines ETL ?
L'automatisation de votre pipeline de données présente de nombreux avantages. Nombre d'entre eux mettent en évidence l'amélioration de l'efficacité des communications au sein de l'entreprise et le retour d'information pour soutenir l'innovation intelligente.
Gain de temps et de ressources
Le principal avantage de l'utilisation d'un pipeline ETL est que vous pouvez automatiser le processus en écrivant des scripts pour effectuer toutes vos transformations en un seul endroit. Vous êtes ainsi assuré d'obtenir des résultats cohérents dans tous vos systèmes, ce qui signifie que vous passerez moins de temps à effectuer manuellement des tâches telles que la création de rapports à l'aide de feuilles de calcul Excel ou la copie manuelle de fichiers entre différentes applications.
Imaginez que le temps passé par vos employés à collecter et à nettoyer des données soit soudainement libéré. Cela signifie que les tâches fastidieuses et répétitives de collecte de données n'encombrent plus votre équipe. Par conséquent, ils sont libres de travailler sur des opérations créatives et managériales.
Réduire les erreurs et clarifier les données
Vous avez également un bien meilleur contrôle sur ce qu'il advient de vos données. S'il y a des erreurs dans le processus de transformation, vous les récupérez avant même qu'elles ne quittent votre système. Par conséquent, les points d'arrivée de vos données - là où vos services ou produits entrent en contact avec les clients - respectent leur retour d'information.
Élimination de la redondance
Enfin, tout se passe dans un script unique. Cela signifie que vous n'avez pas à vous préoccuper du fait que plusieurs personnes travaillent en même temps sur le même rapport. Il vous suffit d'écrire un script et de laisser tout le monde l'exécuter.
Comment mettre en place des pipelines ETL dans votre entreprise.
De nombreuses entreprises ont commencé à mettre en œuvre des processus ETL dans leurs activités. Les principales raisons sont les suivantes :
- Le besoin de cohérence des données et la capacité d'extraire des informations de différentes sources dans une base de données ou un système unique.
- Vous pouvez résoudre les problèmes de qualité des données grâce à des processus automatisés qui analysent les données et produisent des rapports. Cela vous permettra d'améliorer les performances de votre organisation, de réduire les coûts et d'accroître la satisfaction des clients.
- La nécessité de disposer d'informations précises et opportunes sur vos clients. Cela vous aidera à améliorer le service à la clientèle, à réduire les coûts et à accroître la satisfaction des clients. L'exactitude des données est l'un des facteurs les plus importants qui déterminent l'efficacité future de votre entreprise.
Mais comment faire fonctionner la raffinerie de données qu'est un pipeline ETL ?
Vous pouvez commencer par récolter des ensembles de données sur des plateformes de médias sociaux comme Facebook ou Reddit, et sur des sites d'évaluation comme Yelp.
En interne, vous pouvez collecter des données clés à partir des courriers électroniques et utiliser ces informations pour identifier les lacunes dans les services et les produits. À partir de là, vous pouvez établir une liste de priorités à traiter.
À plus grande échelle, il est possible d'alimenter automatiquement votre entreprise en données provenant de l'ensemble de l'internet. Vous pouvez ensuite les organiser dans des formats lisibles tels que les PDF, les feuilles de calcul Excel ou les fichiers CVS.
Pour en savoir plus sur les sources de données, consultez notre Guide complet des ensembles de données. Mais pour l'instant, nous allons vous présenter les grandes lignes de la collecte de données à l'aide de scripts logiciels automatisés appelés « web scrapers ».
Automatisation des pipelines ETL à l'aide d'outils de scraping web.
L'automatisation de votre pipeline ETL à l'aide d'outils de web scraping est un processus qui vous permet d'automatiser toutes les étapes de votre pipeline de traitement des données.
- Collecte de données via l'exploration et le grattage du web
- Nettoyage des données, par exemple en supprimant les doublons ou les mauvais enregistrements de votre ensemble de données
- Analyse et nettoyage des fichiers texte
- Chargement de fichiers CSV dans des bases de données
- Visualisation de données, comme la création de diagrammes à barres et de graphiques
Vous pouvez effectuer toutes ces étapes manuellement, à l'aide d'outils distincts, mais cela demande beaucoup d'apprentissage et peut entraîner de nombreuses erreurs si vous ne savez pas ce que vous faites.
Il existe des services que vous pouvez découvrir dans notre étude sur les outils de scraping et qui se chargent de la majeure partie de ce processus à votre place.
Si vous décidez d'utiliser ces services optimisés, nous vous recommandons de les associer àdes proxys résidentiels rotatifs. En résumé, ils peuvent accélérer le traitement des données, élargir votre champ d'action sur Internet, vous protéger contre les failles de sécurité et contourner les interdictions d'IP.


