
Web scrapers cough up what looks like half-digested alphabet soup.
Gross.
One might assume gastrointestinal troubles, but that’s not quite it.
Web scrapers process data in an unstructured format, so what you get’s an HTML document or some other mess.
Enter data parsing.
Data parsing is a method web scrapers use to take web pages and convert them into a more readable format. It's an essential step in web scraping because otherwise, the data would be difficult to read and analyze.
Parsing is essential to read computer language. As you’ll soon see – it’s also essential in the comprehension of reality.
Parsing defined
The term [data] parsing comes from the Latin word pars (orationis), meaning part of speech. It can have slightly different meanings in different branches of linguistics and computer science.
Psycholinguistics uses the term to discuss which oral cues help a speaker interpret garden-path sentences. In another language, the term parsing can also mean a split or separation.
Wow, more than you want to know right?
All that to say parse means to split speech into parts.
Suppose we define parsing in the language of computer programming. (Have I aroused your interest now?)
In that case, you refer to how you read and process a string of symbols, including special characters, to help you understand what you’re trying to accomplish.
Parsing has different definitions for linguists and computer programmers. Still, the general consensus is that it means analyzing sentences and semantic mapping relationships between them. In other words, parsing is the filtering and filing of data structures.
What’s data parsing?
The term parsing data describes the processing of unstructured data and its conversion into a new structured format.
The parsing process is everywhere. Your brain is continuously parsing data from your nervous system.
But instead of DNA programs parsing pain and pleasure to promote the generation of life – parsers in the context of this article convert received data from web scraping results.
(Cue disappointment)
However, in both cases, we need to adapt one data format into a form capable of being understood. Whether that’s producing reports from HTML strings or sensory gating.
The structure of a data parser
Data parsing usually involves two essential phases: lexical analysis and syntactic analysis. These steps transform a string of unstructured data into a tree of data whose rules and syntax integrate into the tree’s structure.
Lexical analysis
Lexical analysis in its simplest form assigns a token to each piece of data. The tokens or lexical units include keywords, delimiters, and other identifiers.
Let’s say you have a long line of creatures boarding a ship. As they pass through the gate, each creature gets a token. The elephant gets the ‘enormous land animal token,’ and the alligator gets the ‘dangerous amphibian token.’

Then we know where to put each creature on the ship, so no one gets hurt on the sun cruise vacation.
In the data parsing world, lexical units are assigned to unstructured data. For instance, a word in an HTML string will get a word token and so on. Irrelevant tokens contain elements like parenthesis, curly braces, and semicolons. Then you can organize the data by token type.
As you can see, lexical analysis is a crucial step to delivering accurate data for syntactic analysis.
And keeping gators in check.
Syntactic analysis
Syntax analysis is the process of constructing a parse tree. If you’re familiar with HTML, then this will be easy for you to understand. For instance, let’s say we parse an HTML web page and create a document object model (DOM). The text between tags becomes child nodes or branches on the parse tree, while attributes become branch properties.
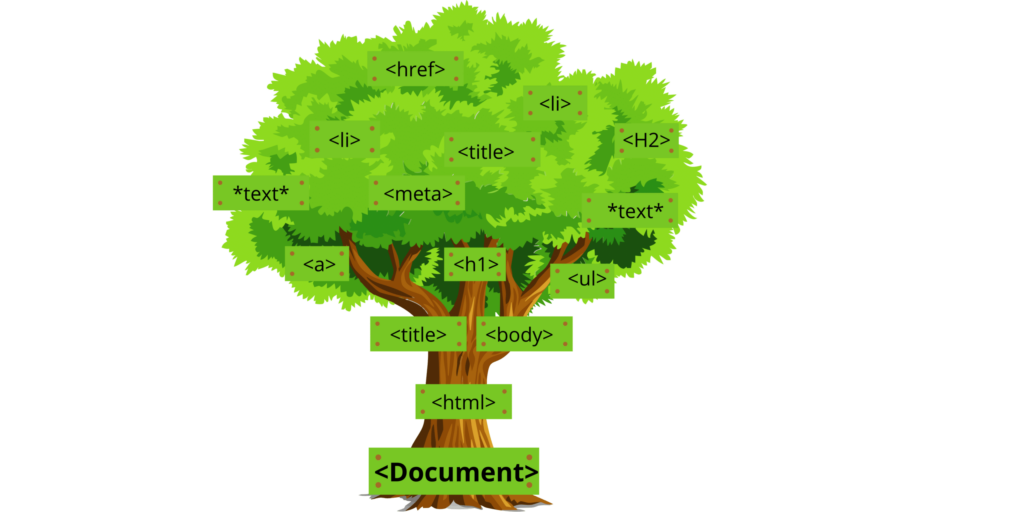
The syntactic analysis phase creates data structures that make sense of what was formerly just raw string data. This stage also groups all tokens by type – either keywords or identifiers like parenthesis, curly braces, etcetera. So each token has its own node within the larger structure being built by your parser tool.
Semantic Analysis
Semantic analysis is a step that’s not implemented in most web scraping tools. It allows you to extract data from HTML by identifying different parts of speech like nouns, verbs, and other roles within sentences.
But let’s go back to parsing our web page with syntax rules for this discussion on semantic analysis. The parser will break down each sentence into its correct form. Then it’ll continue building nodes until it reaches the end tag or closing curly brace ‘}’ – which signifies the end of an element.
The parse tree would show you what elements are at play. For example – what words make up your web page content – but nothing about interpretation (semantics) because no values were assigned during syntactic parsing. For this, you have to go back and parse the web page elements again.
Types of data parsers
Top-down and bottom-up parsers are two different strategies for data parsing.
Top-down parsing is a way to understand sentences by looking at the most minor parts and then working your way up. This is called the primordial soup approach. It’s very similar to sentence diagramming, which breaks down the constituents of sentences. One kind of this type of parser is LL parsers.
Bottom-up parsing starts from the end and works its way up, finding the most fundamental parts first. One kind of this type of parser is called LR parsers.
To build or to buy?
Like cooking macaroni and cheese, sometimes it’s cheaper to make your own rather than buy the product. When it comes to data parsers, the question is not as easy to answer. There are more things to consider when choosing to construct or purchase tools for data extraction. Let’s look at potential and outcome with both options with both possibilities available.

Buying a data parser
The web is full of parsing technologies. You can buy a parser and get results quickly at an affordable price. The downside to this approach is that if you want your software working on different platforms or for other purposes, you will need to purchase more than one product.
This can get costly over time, and depending on your team’s goals and resources, it may not be practical. There are both free and paid data parsing tools available. Still, it all depends on what your team needs, so keep these in mind when looking into buying a web service rather than developing custom code yourself.
Outsourcing pros
- Purchasing a data parser gives you access to parsing technologies from an organization specializing in data extraction. More of their resources go towards the enhancement and effectiveness of data parsing.
- You have more time and resources available because you won’t need to invest in a team or spend time maintaining your own parser. There’s less chance that you’ll have issues.
Outsourcing cons
- You likely won’t get enough opportunities to personalize your data parser to meet business needs.
- The cost for any customization may arise if you outsource your programming.
Building a data parser
Building your own data parser is beneficial, but it can consume too much energy and resources. Particularly if you need a complex data parsing process to parse large data structures. The development and maintenance require a capable and experienced development team. The last time I checked, a data scientist isn’t cheap!

Building a data parser requires skills such as:
- Natural language processing
- Data scraping
- Web development
- Parse tree building
You or your team will need to be fluent in programming languages and parsing technologies.
In-house pros
- In-house parsers are effective because they are customizable.
- Sourcing your data parser in-house will give you complete control over maintenance and updates.
- If data parsing is a significant component of your business, it will be more cost-efficient in the long run.
You also benefit from using your own product anywhere after developing, which is essential when building data parsers vs. buying one. If you buy a parser, you are locked into their platform, like Google Sheets.
In-house cons
- It’s time-consuming to maintain, update or test your own parser. For example, editing and testing your own parser will require a server capable of supporting the necessary resources.
What tools do you need for data parsing?

If you’re going to build a web scraper, you’ll need a data parsing library with the correct programming language. Ruby, Python, JavaScript (Node.js), Java, and C++ are options depending on what programming language you want to utilize for your data parsing project.
These programming languages work with the web-crawling framework Nokogiri or web frameworks such as Django or Flask in the case of Python.
Or, if you’re going with Ruby, you can choose between Nokigiri and Cheerio, which provides an API that works well alongside Rails web applications.
For Node.js programming, JSoup can be used, while Scrapy is another option for web crawling here too!
Let’s take a closer look:

Nokogiri
Nokogiri lets you work with HTML with Ruby. It has an API similar to the other packages of other languages, which allows you to query the data you retrieve from web scraping. It treats each document with default encryption that adds an extra layer of security. You can use Nokogiri with web frameworks such as Rails, Sinatra, and Titanium.

Cheerio
Cheerio is a great option for Node.js data parsing. It provides an API that you can use to explore and change the data structure of your web scaping results. It does not have a visual rendering, apply CSS, or load external resources as a browser would. Cheerio has many advantages over other frameworks, including better dealing with broken markup languages than most alternatives while still providing fast processing speeds!

JSoup
JSoup allows you to use HTML graphical data via an API for retrieving, extracting, and manipulating URLs. This functions as a browser and as a parser of web pages. Even though it’s often difficult to find other open-source Java options, it’s definitely worth considering.

BeautifulSoup
BeautifulSoup is a Python library to pull data from HTML and XML files. This web-crawling framework is so helpful when it comes to parsing web data. It’s compatible with web frameworks such as Django and Flask.

Scrapy
Scrapy is a web crawling framework written in Python available through PyPI. It makes it very simple to write web crawlers while being powerful enough to do custom tasks. Scrapy can also be used as its own web scraping library.

Parsimonious
The Parsimonious library uses the parsing expression grammar (PEG). You can use this parser in Python or Ruby on Rails applications. PEGs are commonly found in some web frameworks and parsers due to their simplicity compared with context-free grammars. But they have limitations when trying to parse languages without whitespaces between some words like C++ code samples.

LXML
Lxml is another Python XML parser that allows you to traverse the structure of data from web pages. It also includes many extra features for HTML parsing and XPath queries, which can help when scraping web results. It’s been used in many projects by NASA and Spotify, so its popularity certainly speaks for itself!
You should get inspired by these options before deciding which one will work better for your team!
Preventing web scraping blocks
It’s a common problem to get blocked web scraping. Some people simply do not want the load and risk that comes with robot visitors. (Pesky bots!) You can learn more about it here.
The way forward is to use rotating residential proxies. Many web scraping APIs include them, but you should be familiar with proxies if you plan to build your own parser.
This article will tell you all about residential proxies and how you can use them for data extraction.
Use cases for data parsing
Now you know the benefits of using a parser to convert web pages into an easy-to-read format. Let’s look at some use cases that might help your team out.

Web security
You may want to keep data safe from hackers by encrypting any sensitive information in your data files before sending them over the internet or storing them on devices. You can parse data logs and scan for traces of malware or other viruses.

Web development
The web is becoming more complex, so it’s important to parse data and use logging tools to understand how users interact with web pages. The web development industry will continue growing as we see mobile apps become a large part of our lives.

Data extraction
Data parsing is a crucial practice for data extraction. Web scraping can be very time-consuming, and it’s important to parse the data as soon as possible, so your project stays on schedule. For any web development or data mining projects, you’ll need to know how to use a data parser correctly!

Investment analysis
Investors can efficiently exploit data aggregation so that they can make better business decisions. Investors, hedge funds, or others that assess start-up companies, predict earnings and even control social sentiment rely on robust data extraction techniques.
Web scrapers and parsing tools make it fast and efficient. They optimize workflow and allow you to direct resources elsewhere or focus on more deep data analysis such as equity research and competitive analysis. For more information about web scraping tools – click here.

Registry analysis
Registry analysis is an instrumental and powerful technique in searching for malware in an image. In addition to persistence mechanisms, malware often has additional artifacts that you can look for. These artifacts include values under the MUICache key, prefetch files, the Dr. Watson data files, and other objects. These and different types of malware can provide indications in such cases that antivirus programs cannot detect.

Real estate
A parser can benefit a real estate company through contact details, property addresses, cash flow data, and lead sources.

Finance and Accounting
Data exploitation is used to analyze credit score and investment portfolio data and obtain better insights into customer interactions with other users. Finance companies use parsing to determine the rate and period of debt repayment after extracting the data.
You can also use data parsing for research purposes to determine interest rates, the return rate of loan payments, and the interest rate of bank deposits.

Business workflow optimization
Data parsers are used by companies to analyze unstructured data into useful information. Data mining allows companies to optimize workflows and capitalize on extensive data analysis. You can use parsing in advertising, social marketing, social media management, and other business applications.

Shipping and Logistics
Businesses that provide goods and services on the web utilize data scraping to extract billing details. They use parsers to arrange shipping labels and to verify that formatting has been corrected.

Artificial Intelligence
Natural Language Processing (NLP) is at the forefront of artificial intelligence and machine learning. It’s an avenue of data parsing that helps computers understand human language.
There are so many more uses. As we continue into the digital age, the difference between computer code and organic data grows smaller and smaller.
For more information about web scraping and data parsing – visit more of our blog.


