
網路刮板咳出看起來像是半消化的字母湯。
總。
人們可能會認為胃腸道問題,但事實並非如此。
網路抓取工具以非結構化格式處理數據,因此您得到的是HTML文檔或其他混亂。
輸入數據解析。
數據解析是網路抓取工具用來獲取網頁並將其轉換為更具可讀性的格式的一種方法。這是網路抓取中必不可少的一步,否則,數據將難以讀取和分析。
解析對於閱讀計算機語言至關重要。正如你很快就會看到的——這對於理解現實也是必不可少的。
解析定義
術語[data]解析來自拉丁語pars(orationis),意思是詞性的一部分。它在語言學和計算機科學的不同分支中的含義可能略有不同。
心理語言學使用該術語來討論哪些口頭線索可以幫助說話者解釋花園路徑句子。在另一種語言中,術語解析也可以表示拆分或分離。
哇,比你想知道的還要多,對吧?
總而言之,parse意味著將語音分成幾部分。
假設我們用計算機程式設計語言來定義解析。(我現在引起你的興趣了嗎?
在這種情況下,您可以參考如何讀取和處理一串符號(包括特殊字元),以説明您瞭解要完成的任務。
解析對語言學家和計算機程式師有不同的定義。儘管如此,普遍的共識是,這意味著分析句子和它們之間的語義映射關係。換句話說,解析是數據結構的過濾和歸檔。
什麼是數據解析?
術語解析數據描述了非結構化數據的處理及其轉換為新的結構化格式。
解析過程無處不在。你的大腦不斷地解析來自神經系統的數據。
但是,本文上下文中的解析器不是解析痛苦和快樂以促進生命的產生 - 本文上下文中的解析器轉換從網路抓取結果中接收到的數據。
(提示失望)
However, in both cases, we need to adapt one data format into a form capable of being understood. Whether that’s producing reports from HTML strings or sensory gating.
數據分析器的結構
數據解析通常涉及兩個基本階段:詞法分析和句法分析。這些步驟將一串非結構化數據轉換為數據樹,其規則和語法集成到樹的結構中。
詞法分析
Lexical analysis in its simplest form assigns a token to each piece of data. The tokens or lexical units include keywords, delimiters, and other identifiers.
假設你有一長串的生物登上一艘船。當他們通過大門時,每個生物都會得到一個令牌。大象獲得「巨大的陸地動物令牌」,鱷魚獲得「危險的兩棲動物令牌」。。

然後我們知道將每個生物放在船上的哪個位置,這樣就不會有人在陽光巡航假期受傷。
在數據解析世界中,詞法單位被分配給非結構化數據。例如,HTML 字串中的單詞將獲得單詞標記,依此類推。不相關的標記包含括弧、大括弧和分號等元素。然後,您可以按令牌類型組織數據。
如您所見,詞法分析是為句法分析提供準確數據的關鍵步驟。
並控制鱷魚。
句法分析
Syntax analysis is the process of constructing a parse tree. If you’re familiar with HTML, then this will be easy for you to understand. For instance, let’s say we parse an HTML web page and create a document object model (DOM). The text between tags becomes child nodes or branches on the parse tree, while attributes become branch properties.
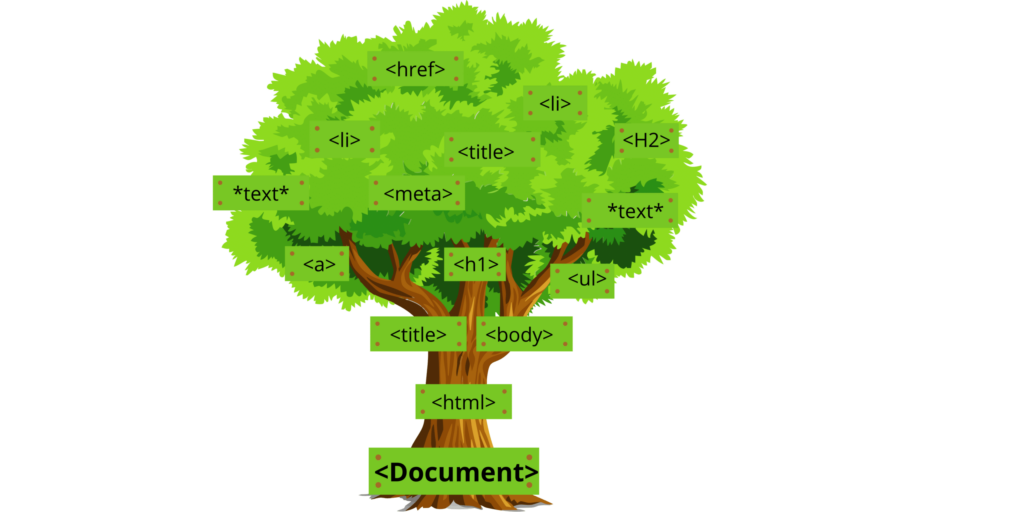
句法分析階段創建數據結構,這些結構可以理解以前只是原始字串數據的內容。此階段還按類型對所有令牌進行分組 - 關鍵字或標識符,如括弧、大括弧等。因此,每個令牌在解析器工具構建的較大結構中都有自己的節點。
語義分析
語義分析是大多數網路抓取工具中未實現的步驟。它允許您通過識別不同的詞性(如名詞、動詞和句子中的其他角色)從 HTML 中提取數據。
但是,讓我們回到使用語法規則解析我們的網頁,以討論語義分析。解析器會將每個句子分解為正確的形式。然後它將繼續構建節點,直到到達結束標記或右大括弧“}”——表示元素的結束。
解析樹將向您顯示哪些元素在起作用。例如 – 哪些單詞構成了您的網頁內容 – 但與解釋(語義)無關,因為在句法解析期間沒有分配任何值。為此,您必須返回並再次解析網頁元素。
數據分析器的類型
自上而下和自下而上的解析器是兩種不同的數據解析策略。
Top-down parsing is a way to understand sentences by looking at the most minor parts and then working your way up. This is called the primordial soup approach. It’s very similar to sentence diagramming, which breaks down the constituents of sentences. One kind of this type of parser is LL parsers.
Bottom-up parsing starts from the end and works its way up, finding the most fundamental parts first. One kind of this type of parser is called LR parsers.
建造還是購買?
就像烹飪通心粉和乳酪一樣,有時自己製作比購買產品更便宜。當涉及到數據分析器時,這個問題並不容易回答。在選擇構建或購買數據提取工具時,需要考慮更多事項。讓我們看看兩種可能性的可能性和結果。

購買數據分析器
網路上充滿了解析技術。您可以購買解析器並以實惠的價格快速獲得結果。這種方法的缺點是,如果您希望您的軟體在不同的平臺上運行或用於其他目的,則需要購買多個產品。
隨著時間的推移,這可能會變得昂貴,並且根據團隊的目標和資源,它可能不切實際。有免費和付費的數據解析工具可用。不過,這完全取決於您的團隊需要什麼,因此在考慮購買 Web 服務而不是自己開發自定義代碼時請記住這些。
外包專業人士
- 購買數據分析器后,您可以訪問專門從事數據提取的組織提供的解析技術。他們的更多資源用於增強數據解析和有效性。
- 您有更多的時間和資源可用,因為您無需投資團隊或花時間維護自己的解析器。您遇到問題的可能性較小。
外包缺點
- 您可能沒有足夠的機會來個人化您的數據分析器以滿足業務需求。
- 如果您將程式設計外包,則可能會產生任何自定義的成本。
構建數據分析器
構建自己的數據解析器是有益的,但它會消耗太多的能源和資源。特別是如果您需要複雜的數據解析過程來解析大型數據結構。開發和維護需要一個有能力和經驗豐富的開發團隊。我上次檢查時,數據科學家並不便宜!

構建資料分析器需要以下技能:
- 自然語言處理
- 數據抓取
- 網站開發
- 解析樹構建
您或您的團隊需要精通程式設計語言和解析技術。
內部專業人士
- 內部解析器是有效的,因為它們是可定製的。
- 在內部採購數據解析器將使您能夠完全控制維護和更新。
- 如果數據解析是您業務的重要組成部分,那麼從長遠來看,它將更具成本效益。
您還可以在開發后的任何地方使用自己的產品,這在構建數據解析器與購買數據解析器時至關重要。如果您購買解析器,您將被鎖定在他們的平臺中,例如Google表格。
內部缺點
- 維護、更新或測試您自己的解析器非常耗時。例如,編輯和測試您自己的解析器將需要能夠支援必要資源的伺服器。
數據解析需要哪些工具?

如果您要構建網路爬蟲,則需要具有正確程式設計語言的數據解析庫。Ruby,Python,JavaScript(Node.js),Java和C++是選項,具體取決於要用於數據解析專案的程式設計語言。
These programming languages work with the web-crawling framework Nokogiri or web frameworks such as Django or Flask in the case of Python.
Or, if you’re going with Ruby, you can choose between Nokigiri and Cheerio, which provides an API that works well alongside Rails web applications.
For Node.js programming, JSoup can be used, while Scrapy is another option for web crawling here too!
讓我們仔細看看:

野古吉里
Nokogiri 允許您使用 Ruby。它具有類似於其他語言的其他軟體包的API,它允許您查詢從網路抓取中檢索的數據。它使用預設加密處理每個文件,從而增加了額外的安全層。您可以將Nokogiri與Rails,Sinatra和Titanium等Web框架一起使用。

再見
Cheerio 是 Node .js 數據解析的絕佳選擇。它提供了一個 API,可用於瀏覽和更改 Web 分景結果的數據結構。它沒有像瀏覽器那樣的可視化渲染、應用 CSS 或載入外部資源。與其他框架相比,Cheerio 具有許多優勢,包括比大多數替代方案更好地處理損壞的標記語言,同時仍然提供快速的處理速度!

JSoup
JSoup 允許您通過 API 使用 HTML 圖形數據來檢索、提取和操作 URL。它用作瀏覽器和網頁的解析器。儘管通常很難找到其他開源 Java 選項,但絕對值得考慮。

美麗湯
BeautifulSoup is a Python library to pull data from HTML and XML files. This web-crawling framework is so helpful when it comes to parsing web data. It’s compatible with web frameworks such as Django and Flask.

刮擦
Scrapy is a web crawling framework written in Python available through PyPI. It makes it very simple to write web crawlers while being powerful enough to do custom tasks. Scrapy can also be used as its own web scraping library.

吝嗇
The Parsimonious library uses the parsing expression grammar (PEG). You can use this parser in Python or Ruby on Rails applications. PEGs are commonly found in some web frameworks and parsers due to their simplicity compared with context-free grammars. But they have limitations when trying to parse languages without whitespaces between some words like C++ code samples.

LXML
Lxml is another Python XML parser that allows you to traverse the structure of data from web pages. It also includes many extra features for HTML parsing and XPath queries, which can help when scraping web results. It’s been used in many projects by NASA and Spotify, so its popularity certainly speaks for itself!
在決定哪個更適合您的團隊之前,您應該從這些選項中獲得靈感!
防止網頁抓取塊
It’s a common problem to get blocked web scraping. Some people simply do not want the load and risk that comes with robot visitors. (Pesky bots!) You can learn more about it here.
The way forward is to use rotating residential proxies. Many web scraping APIs include them, but you should be familiar with proxies if you plan to build your own parser.
This article will tell you all about residential proxies and how you can use them for data extraction.
數據解析用例
現在您知道使用解析器將網頁轉換為易於閱讀的格式的好處。讓我們看一些可能對您的團隊有所説明的用例。

網路安全
您可能希望在通過互聯網發送數據檔或將其存儲在設備上之前加密數據檔中的任何敏感資訊,從而保護數據免受駭客攻擊。您可以分析數據日誌並掃描惡意軟體或其他病毒的痕跡。

網站開發
Web 變得越來越複雜,因此解析數據並使用日誌記錄工具來了解使用者如何與網頁交互非常重要。隨著我們看到移動應用程式成為我們生活的重要組成部分,Web開發行業將繼續增長。

數據提取
數據解析是數據提取的關鍵實踐。網頁抓取可能非常耗時,儘快解析數據非常重要,這樣您的專案才能按計劃進行。對於任何 Web 開發或數據挖掘專案,您都需要知道如何正確使用數據解析器!

投資分析
投資者可以有效地利用數據聚合,以便他們能夠做出更好的業務決策。投資者、對沖基金或其他評估初創公司、預測收益甚至控制社會情緒的人都依賴於強大的數據提取技術。
Web scrapers and parsing tools make it fast and efficient. They optimize workflow and allow you to direct resources elsewhere or focus on more deep data analysis such as equity research and competitive analysis. For more information about web scraping tools – click here.

註冊表分析
Registry analysis is an instrumental and powerful technique in searching for malware in an image. In addition to persistence mechanisms, malware often has additional artifacts that you can look for. These artifacts include values under the MUICache key, prefetch files, the Dr. Watson data files, and other objects. These and different types of malware can provide indications in such cases that antivirus programs cannot detect.

房地產
解析器可以通過聯繫方式、房產位址、現金流數據和潛在客戶來源使房地產公司受益。

財務與會計
數據利用用於分析信用評分和投資組合數據,並更好地瞭解客戶與其他用戶的互動。財務公司在提取數據后使用解析來確定債務償還的速率和期限。
您還可以將數據解析用於研究目的,以確定利率、貸款支付回報率和銀行存款利率。

業務工作流優化
公司使用數據分析器將非結構化數據分析為有用的資訊。數據挖掘使公司能夠優化工作流程並利用廣泛的數據分析。您可以在廣告、社交行銷、社交媒體管理和其他業務應用程式中使用解析。

航運和物流
在網路上提供商品和服務的企業利用數據抓取來提取帳單詳細資訊。他們使用解析器來排列發貨標籤並驗證格式是否已更正。

人工智慧
Natural Language Processing (NLP) is at the forefront of artificial intelligence and machine learning. It’s an avenue of data parsing that helps computers understand human language.
還有更多的用途。隨著我們繼續進入數位時代,計算機代碼和有機數據之間的差異越來越小。
For more information about web scraping and data parsing – visit more of our blog.


