
Веб-скреперы выкашливают то, что выглядит как полупереваренный алфавитный суп.
Брутто.
Можно было бы предположить желудочно-кишечные проблемы, но это не совсем так.
Веб-скреперы обрабатывают данные в неструктурированном формате, так что в результате получается HTML-документ или какая-нибудь другая каша.
Ввести парсинг данных.
Парсинг данных - это метод, с помощью которого веб-скраперы берут веб-страницы и преобразуют их в более удобный для чтения формат. Это очень важный этап в работе с веб-страницами, поскольку в противном случае данные будет трудно читать и анализировать.
Парсинг необходим для чтения компьютерного языка. Как вы вскоре увидите, он также необходим для понимания реальности.
Парсинг определен
Термин "синтаксический анализ данных" происходит от латинского слова pars (orationis), означающего часть речи. В различных отраслях лингвистики и информатики он может иметь несколько иное значение.
В психолингвистике этот термин используется для обсуждения того, какие устные подсказки помогают говорящему интерпретировать предложения с садовой дорожкой. В других языках термин "синтаксический разбор" может также означать расщепление или разделение.
Вау, больше, чем вы хотите знать, верно?
Все это означает, что разбор означает разделение речи на части.
Предположим, что мы определяем синтаксический анализ на языке компьютерного программирования. (Я уже вызвал у вас интерес?)
В этом случае вы обращаетесь к тому, как читается и обрабатывается строка символов, в том числе и специальных, чтобы помочь вам понять, чего вы пытаетесь достичь.
Парсинг имеет разные определения для лингвистов и программистов. Однако общее мнение сводится к тому, что он означает анализ предложений и семантическое отображение связей между ними. Другими словами, синтаксический анализ - это фильтрация и фильтрация структур данных.
Что такое парсинг данных?
Термин "синтаксический анализ данных" описывает обработку неструктурированных данных и их преобразование в новый структурированный формат.
Процесс синтаксического анализа происходит повсеместно. Ваш мозг постоянно анализирует данные, поступающие от нервной системы.
Но вместо того, чтобы программы ДНК разбирали боль и удовольствие, способствуя зарождению жизни, - парсеры в контексте данной статьи преобразуют полученные данные из результатов веб-скрапинга.
(Разочарование).
However, in both cases, we need to adapt one data format into a form capable of being understood. Whether that’s producing reports from HTML strings or sensory gating.
Структура синтаксического анализатора данных
Разбор данных обычно включает в себя два основных этапа: лексический анализ и синтаксический анализ. На этих этапах строка неструктурированных данных преобразуется в дерево данных, правила и синтаксис которого интегрируются в структуру дерева.
Лексический анализ
Lexical analysis in its simplest form assigns a token to each piece of data. The tokens or lexical units include keywords, delimiters, and other identifiers.
Допустим, у вас есть длинная очередь существ, садящихся на корабль. Когда они проходят через ворота, каждое существо получает жетон. Слон получает жетон "огромное сухопутное животное", а аллигатор - "опасное земноводное".

Тогда мы знаем, где разместить каждое существо на корабле, чтобы никто не пострадал во время отдыха в солнечном круизе.
В мире синтаксического анализа данных неструктурированным данным присваиваются лексические единицы. Например, слово в HTML-строке получает лексему word и так далее. Нерелевантные лексемы содержат такие элементы, как круглые скобки, фигурные скобки и точки с запятой. Затем данные можно упорядочить по типу токенов.
Как видно, лексический анализ является важнейшим этапом, обеспечивающим получение точных данных для синтаксического анализа.
И держать в узде аллигаторов.
Синтаксический анализ
Syntax analysis is the process of constructing a parse tree. If you’re familiar with HTML, then this will be easy for you to understand. For instance, let’s say we parse an HTML web page and create a document object model (DOM). The text between tags becomes child nodes or branches on the parse tree, while attributes become branch properties.
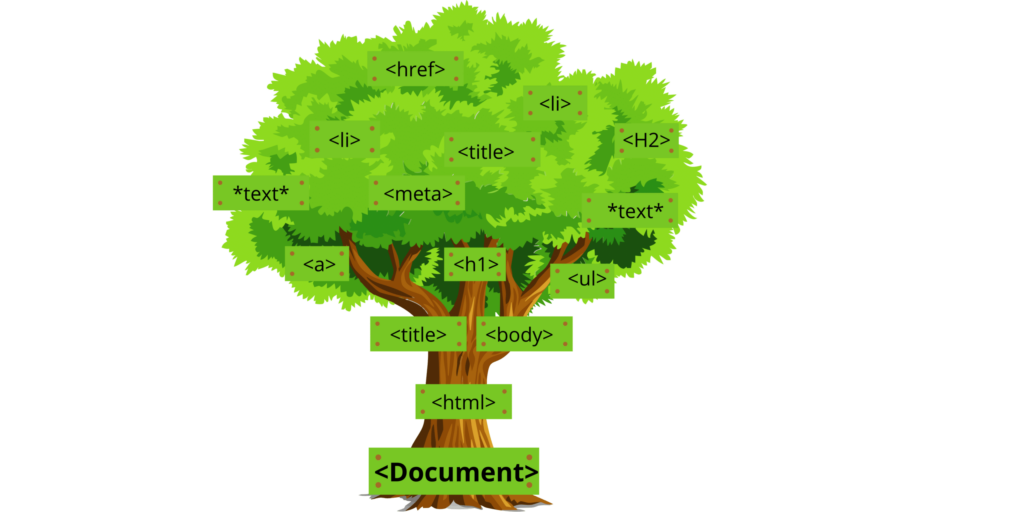
На этапе синтаксического анализа создаются структуры данных, которые наполняют смыслом то, что раньше было просто необработанными строковыми данными. На этом этапе все лексемы также группируются по типу - либо ключевые слова, либо идентификаторы, такие как круглые скобки, фигурные скобки и т.д. Таким образом, каждая лексема имеет свой узел в более крупной структуре, создаваемой вашим инструментом синтаксического анализа.
Семантический анализ
Семантический анализ - это этап, который не реализован в большинстве инструментов для веб-скрапинга. Он позволяет извлекать данные из HTML путем определения различных частей речи, таких как существительные, глаголы и другие роли в предложениях.
Но вернемся к разбору нашей веб-страницы с помощью синтаксических правил для обсуждения семантического анализа. Парсер разбивает каждое предложение на правильные формы. Затем он будет продолжать строить узлы, пока не достигнет тега end или закрывающей фигурной скобки '}', которая означает конец элемента.
Дерево синтаксического разбора покажет, какие элементы в нем присутствуют. Например, какие слова составляют содержимое веб-страницы, но ничего об интерпретации (семантике), поскольку при синтаксическом разборе не было присвоено никаких значений. Для этого необходимо вернуться и снова разобрать элементы веб-страницы.
Типы парсеров данных
Нисходящий и восходящий парсеры - это две разные стратегии разбора данных.
Top-down parsing is a way to understand sentences by looking at the most minor parts and then working your way up. This is called the primordial soup approach. It’s very similar to sentence diagramming, which breaks down the constituents of sentences. One kind of this type of parser is LL parsers.
Bottom-up parsing starts from the end and works its way up, finding the most fundamental parts first. One kind of this type of parser is called LR parsers.
Строить или покупать?
Как и при приготовлении макарон с сыром, иногда дешевле сделать самому, чем покупать готовый продукт. Когда речь идет о парсерах данных, ответить на этот вопрос не так просто. При выборе между созданием или приобретением инструментов для извлечения данных необходимо учитывать большее количество факторов. Давайте рассмотрим потенциал и результат при использовании обоих вариантов.

Покупка парсера данных
В Интернете представлено множество технологий парсинга. Вы можете купить парсер и быстро получить результат по доступной цене. Недостатком такого подхода является то, что если вы хотите, чтобы ваше программное обеспечение работало на разных платформах или для других целей, то вам придется приобрести несколько продуктов.
Со временем это может оказаться дорогостоящим и, в зависимости от целей и ресурсов вашей команды, нецелесообразным. Существуют как бесплатные, так и платные средства анализа данных. Но все зависит от того, что нужно вашей команде, поэтому имейте их в виду, когда будете покупать веб-сервис, а не разрабатывать собственный код.
Профессионалы в области аутсорсинга
- Приобретая парсер данных, вы получаете доступ к технологиям парсинга от организации, специализирующейся на извлечении данных. Больше ресурсов этой организации направляется на совершенствование и повышение эффективности парсинга данных.
- У вас больше времени и ресурсов, поскольку вам не нужно вкладывать средства в команду или тратить время на поддержку собственного парсера. Меньше вероятность возникновения проблем.
Минусы аутсорсинга
- Скорее всего, у вас не будет достаточно возможностей для персонализации парсера данных в соответствии с потребностями бизнеса.
- При передаче программирования на аутсорсинг могут возникнуть расходы на доработку.
Построение парсера данных
Создание собственного парсера данных полезно, но может потребовать слишком много энергии и ресурсов. Особенно если требуется сложный процесс парсинга данных для разбора больших структур данных. Разработка и сопровождение требуют наличия опытной команды разработчиков. Насколько я знаю, специалист по анализу данных стоит недешево!

Построение синтаксического анализатора данных требует таких навыков, как:
- Обработка естественного языка
- Сокращение данных
- Веб-разработка
- Построение дерева разбора
От вас или вашей команды потребуется свободное владение языками программирования и технологиями синтаксического анализа.
Штатные специалисты
- Собственные парсеры эффективны потому, что они настраиваются.
- Приобретение парсера данных собственными силами позволит полностью контролировать его обслуживание и обновление.
- Если парсинг данных является существенной составляющей вашего бизнеса, то в долгосрочной перспективе он будет более рентабельным.
Кроме того, вы получаете возможность использовать свой собственный продукт в любом месте после разработки, что очень важно при создании парсеров данных по сравнению с покупкой. Если вы покупаете парсер, вы привязываетесь к его платформе, как, например, Google Sheets.
Внутренние согласования
- Сопровождение, обновление и тестирование собственного парсера требует значительных затрат времени. Например, для редактирования и тестирования собственного парсера потребуется сервер, способный поддерживать необходимые ресурсы.
Какие инструменты нужны для парсинга данных?

Если вы собираетесь создать веб-скрапер, вам понадобится библиотека для парсинга данных с соответствующим языком программирования. Ruby, Python, JavaScript (Node.js), Java и C++ - в зависимости от того, какой язык программирования вы хотите использовать в своем проекте парсинга данных.
These programming languages work with the web-crawling framework Nokogiri or web frameworks such as Django or Flask in the case of Python.
Or, if you’re going with Ruby, you can choose between Nokigiri and Cheerio, which provides an API that works well alongside Rails web applications.
For Node.js programming, JSoup can be used, while Scrapy is another option for web crawling here too!
Рассмотрим их подробнее:

Nokogiri
Nokogiri позволяет работать с HTML с помощью Ruby. Он имеет API, аналогичный пакетам для других языков, который позволяет запрашивать данные, полученные в результате веб-скрапинга. Каждый документ обрабатывается с помощью стандартного шифрования, что добавляет дополнительный уровень безопасности. Nokogiri можно использовать с такими веб-фреймворками, как Rails, Sinatra и Titanium.

Cheerio
Cheerio - отличный вариант для парсинга данных в Node.js. Он предоставляет API, который можно использовать для изучения и изменения структуры данных результатов веб-скейпинга. В нем нет визуального рендеринга, применения CSS или загрузки внешних ресурсов, как это делает браузер. Cheerio имеет множество преимуществ перед другими фреймворками, в том числе лучше справляется с неработающими языками разметки, чем большинство альтернатив, обеспечивая при этом высокую скорость обработки!

JSoup
JSoup позволяет использовать графические данные HTML через API для получения, извлечения и манипулирования URL-адресами. Он функционирует как браузер и как синтаксический анализатор веб-страниц. Несмотря на то, что зачастую трудно найти другие варианты Java с открытым исходным кодом, его определенно стоит рассмотреть.

BeautifulSoup
BeautifulSoup is a Python library to pull data from HTML and XML files. This web-crawling framework is so helpful when it comes to parsing web data. It’s compatible with web frameworks such as Django and Flask.

Scrapy
Scrapy is a web crawling framework written in Python available through PyPI. It makes it very simple to write web crawlers while being powerful enough to do custom tasks. Scrapy can also be used as its own web scraping library.

Парсимония
The Parsimonious library uses the parsing expression grammar (PEG). You can use this parser in Python or Ruby on Rails applications. PEGs are commonly found in some web frameworks and parsers due to their simplicity compared with context-free grammars. But they have limitations when trying to parse languages without whitespaces between some words like C++ code samples.

LXML
Lxml is another Python XML parser that allows you to traverse the structure of data from web pages. It also includes many extra features for HTML parsing and XPath queries, which can help when scraping web results. It’s been used in many projects by NASA and Spotify, so its popularity certainly speaks for itself!
Вы должны вдохновиться этими вариантами, прежде чем решить, какой из них лучше подойдет для вашей команды!
Предотвращение блокировки веб-скрапинга
It’s a common problem to get blocked web scraping. Some people simply do not want the load and risk that comes with robot visitors. (Pesky bots!) You can learn more about it here.
The way forward is to use rotating residential proxies. Many web scraping APIs include them, but you should be familiar with proxies if you plan to build your own parser.
This article will tell you all about residential proxies and how you can use them for data extraction.
Варианты использования парсинга данных
Теперь вы знаете о преимуществах использования парсера для преобразования веб-страниц в удобный для чтения формат. Давайте рассмотрим несколько примеров использования, которые могут помочь вашей команде.

Веб-безопасность
Для защиты данных от хакеров необходимо шифровать конфиденциальную информацию в файлах данных перед их передачей через Интернет или хранением на устройствах. Можно анализировать журналы данных и проверять их на наличие следов вредоносного ПО или других вирусов.

Веб-разработка
Веб становится все более сложным, поэтому важно анализировать данные и использовать инструменты протоколирования, чтобы понять, как пользователи взаимодействуют с веб-страницами. Индустрия веб-разработки будет продолжать развиваться по мере того, как мобильные приложения станут неотъемлемой частью нашей жизни.

Извлечение данных
Парсинг данных - важнейшая практика извлечения данных. Веб-скрапинг может занимать очень много времени, поэтому важно разобрать данные как можно быстрее, чтобы проект не отставал от графика. Для любых проектов по веб-разработке или добыче данных необходимо знать, как правильно использовать парсер данных!

Инвестиционный анализ
Инвесторы могут эффективно использовать агрегацию данных для принятия более эффективных бизнес-решений. Инвесторы, хедж-фонды и другие компании, оценивающие начинающие компании, прогнозирующие прибыль и даже контролирующие социальные настроения, полагаются на надежные методы извлечения данных.
Web scrapers and parsing tools make it fast and efficient. They optimize workflow and allow you to direct resources elsewhere or focus on more deep data analysis such as equity research and competitive analysis. For more information about web scraping tools – click here.

Анализ реестра
Registry analysis is an instrumental and powerful technique in searching for malware in an image. In addition to persistence mechanisms, malware often has additional artifacts that you can look for. These artifacts include values under the MUICache key, prefetch files, the Dr. Watson data files, and other objects. These and different types of malware can provide indications in such cases that antivirus programs cannot detect.

Недвижимость
Парсер может принести пользу риэлторской компании благодаря контактной информации, адресам объектов недвижимости, данным о движении денежных средств и источникам лидов.

Финансы и бухгалтерский учет
Парсинг данных используется для анализа кредитных рейтингов и данных инвестиционного портфеля, а также для получения более полной информации о взаимодействии клиентов с другими пользователями. Финансовые компании после извлечения данных используют парсинг для определения скорости и периода погашения задолженности.
Разбор данных можно также использовать в исследовательских целях для определения процентных ставок, коэффициента возврата платежей по кредитам, процентной ставки по банковским вкладам.

Оптимизация бизнес-процессов
Парсеры данных используются компаниями для анализа неструктурированных данных с целью получения полезной информации. Парсинг данных позволяет компаниям оптимизировать рабочие процессы и извлекать выгоду из обширного анализа данных. Парсинг можно использовать в рекламе, социальном маркетинге, управлении социальными сетями и других бизнес-приложениях.

Грузоперевозки и логистика
Предприятия, предоставляющие товары и услуги в Интернете, используют скрапинг данных для извлечения информации о выставленных счетах. Они используют парсеры для упорядочивания транспортных этикеток и проверки правильности форматирования.

Искусственный интеллект
Natural Language Processing (NLP) is at the forefront of artificial intelligence and machine learning. It’s an avenue of data parsing that helps computers understand human language.
Существует множество других вариантов использования. По мере того как мы продолжаем жить в цифровую эпоху, разница между компьютерным кодом и органическими данными становится все меньше и меньше.
For more information about web scraping and data parsing – visit more of our blog.


