
网络搜索器搜索出来的东西看起来就像被消化了一半的字母汤。
恶心
人们可能会认为是肠胃问题,但事实并非如此。
网络搜刮程序以非结构化格式处理数据,因此得到的是 HTML 文档或其他乱七八糟的东西。
输入数据解析。
数据解析是网络搜刮程序用来获取网页并将其转换为更易读格式的一种方法。这是网络搜刮的重要步骤,否则数据将难以阅读和分析。
解析对于阅读计算机语言至关重要。您很快就会发现,它对理解现实也至关重要。
已定义的解析
数据]解析一词来自拉丁文 pars (orationis),意为语音的一部分。在语言学和计算机科学的不同分支中,该词的含义略有不同。
心理语言学使用该术语来讨论哪些口语线索有助于说话人解释园路句子。在另一种语言中,"解析 "一词也可以指分裂或分离。
哇,比你想知道的还多?
说了这么多,"解析 "的意思就是把语言分成几个部分。
假设我们用计算机编程语言来定义解析。(我现在引起你的兴趣了吗?)
在这种情况下,您可以参考如何读取和处理一串符号,包括特殊字符,以帮助您理解您要实现的目标。
语言学家和计算机程序员对解析有不同的定义。不过,普遍的共识是,它意味着分析句子以及句子之间的语义映射关系。换句话说,解析就是对数据结构进行过滤和归档。
什么是数据解析?
数据解析一词是指处理非结构化数据并将其转换为新的结构化格式。
解析过程无处不在。你的大脑在不断解析来自神经系统的数据。
但是,本文中的解析器不是 DNA 程序解析痛苦和快乐以促进生命的产生,而是将从网络搜刮结果中接收到的数据进行转换。
失望
然而,在这两种情况下,我们都需要将一种数据格式转换为可被理解的形式。无论是从HTML字符串中生成报告,还是进行感官阈值控制。
数据解析器的结构
数据解析通常包括两个基本阶段:词法分析和句法分析。这些步骤将一串非结构化数据转化为数据树,数据树的规则和语法与数据树的结构融为一体。
词汇分析
最简单的词法分析是将每个数据片段分配一个词法单元。这些词法单元包括关键字、分隔符和其他标识符。
假设有一长列生物正在登船。当它们通过闸门时,每个生物都会得到一个令牌。大象得到 "巨大的陆地动物标记",鳄鱼得到 "危险的两栖动物标记"。

这样,我们就知道该把每个生物放在船上的哪个位置,这样就不会有人在阳光邮轮假期中受伤了。
在数据解析领域,词性单位被分配给非结构化数据。例如,HTML 字符串中的一个单词会得到一个单词标记,以此类推。无关标记包含括号、大括号和分号等元素。然后就可以按标记类型组织数据了。
可以看出,词法分析是为句法分析提供准确数据的关键步骤。
并控制鳄鱼
句法分析
语法分析就是构建解析树的过程。如果你熟悉 HTML,那么这一点对你来说很容易理解。例如,假设我们解析一个 HTML 网页并创建一个文档对象模型(DOM)。标签之间的文本会成为解析树上的子节点或分支,而属性则成为分支的属性。
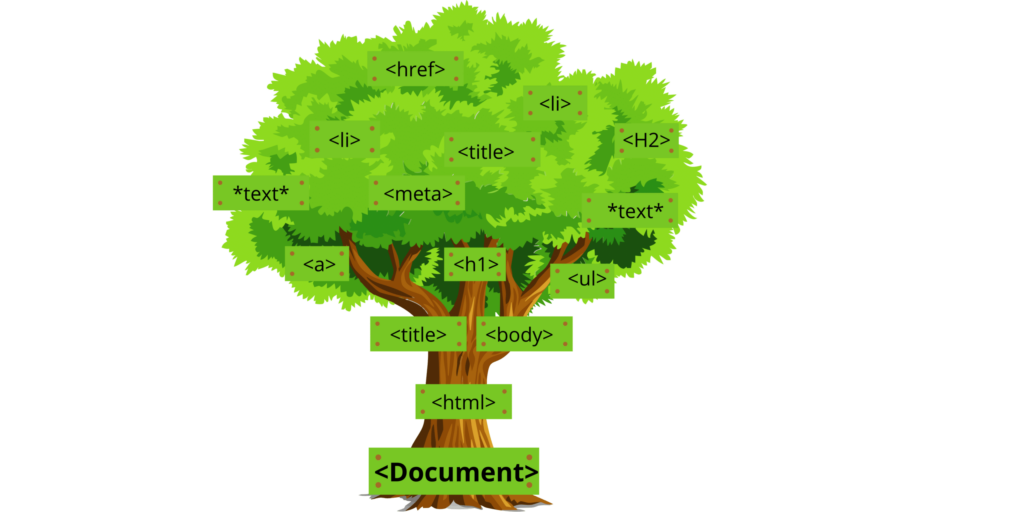
语法分析阶段创建数据结构,使以前的原始字符串数据变得有意义。这一阶段也会按类型对所有标记进行分组,这些标记可以是关键字,也可以是括号、大括号等标识符。这样,在解析器工具构建的更大结构中,每个标记都有自己的节点。
语义分析
语义分析是大多数网络搜刮工具都没有实现的一个步骤。它允许你通过识别不同的语篇(如名词、动词和句子中的其他角色)从 HTML 中提取数据。
不过,在讨论语义分析时,我们还是回到用语法规则解析网页上来。解析器会将每个句子分解为正确的形式。然后,它将继续构建节点,直到到达表示元素结束的结束标记或结尾大括号"}"为止。
解析树会告诉你哪些元素在起作用。例如,网页内容由哪些单词组成,但却没有任何解释(语义),因为在语法分析过程中没有赋值。为此,您必须返回并再次解析网页元素。
数据解析器类型
自上而下和自下而上的解析器是两种不同的数据解析策略。
自上而下解析是一种通过从最细微的部分入手,然后逐步向上推导来理解句子的方式。这被称为“原始汤”方法。它与句子结构分析非常相似,后者是将句子分解为各个组成部分。LL解析器就是此类解析器的一种。
自底向上的解析是从末端开始,逐步向上进行,首先找出最基本的组成部分。此类解析器中的一种被称为LR解析器。
建造还是购买?
就像烹饪通心粉和奶酪一样,有时自己制作比购买便宜。说到数据解析器,这个问题就不那么容易回答了。在选择构建或购买数据提取工具时,需要考虑的事情更多。让我们来看看这两种选择的潜力和结果。

购买数据解析器
网络上充斥着各种解析技术。您可以购买一个解析器,并以合理的价格快速获得结果。这种方法的缺点是,如果您希望您的软件在不同平台上运行或用于其他目的,您就需要购买多个产品。
随着时间的推移,这样做的成本会越来越高,而且根据团队的目标和资源情况,这样做可能并不现实。有免费和付费的数据解析工具可供选择。不过,这完全取决于你的团队需要什么,所以在考虑购买网络服务而不是自己开发定制代码时,请记住这些。
外包专业人员
- 通过购买数据解析器,您可以从专门从事数据提取的机构获得解析技术。他们将更多的资源用于提高数据解析的效率。
- 您有更多的时间和资源,因为您不需要投资一个团队,也不需要花时间维护自己的解析器。出现问题的几率也更小。
外包的弊端
- 您可能没有足够的机会个性化您的数据解析器,以满足业务需求。
- 如果将编程工作外包,可能会产生定制费用。
构建数据解析器
构建自己的数据解析器是有益的,但可能会消耗过多的能源和资源。特别是当你需要一个复杂的数据解析过程来解析大型数据结构时。开发和维护需要一个有能力、有经验的开发团队。据我所知,数据科学家并不便宜!

构建数据解析器需要具备以下技能:
- 自然语言处理
- 数据搜索
- 网络开发
- 解析树构建
您或您的团队需要精通编程语言和解析技术。
内部专业人员
- 内部解析器之所以有效,是因为它们是可定制的。
- 通过内部采购数据解析器,您可以完全控制维护和更新工作。
- 如果数据解析是您业务的重要组成部分,那么从长远来看,它将更具成本效益。
开发完成后,您还可以在任何地方使用自己的产品,这对构建数据解析器和购买数据解析器都至关重要。如果你购买了一个解析器,你就会被锁定在他们的平台上,比如 Google Sheets。
内部弊端
- 维护、更新或测试自己的解析器非常耗时。例如,编辑和测试自己的解析器需要一个能够支持必要资源的服务器。
数据解析需要哪些工具?

如果您要构建一个网络搜刮器,您需要一个使用正确编程语言的数据解析库。Ruby、Python、JavaScript (Node.js)、Java 和 C++ 都是可选语言,这取决于您想在数据解析项目中使用哪种编程语言。
这些编程语言可与网络爬虫框架 Nokogiri 配合使用,就 Python 而言,还可与 Django 或 Flask 等 Web 框架配合使用。
或者,如果你打算使用 Ruby,可以在 Nokigiri 和 Cheerio 之间进行选择,后者提供了一个与 Rails Web 应用程序配合良好的 API。
在 Node.js 编程中,可以使用 JSoup,而 Scrapy 也是网页爬取的另一种选择!
让我们仔细看看:

野切
Nokogiri 可以让你用 Ruby 处理 HTML。它的应用程序接口(API)与其他语言的其他软件包类似,允许你查询从网络搜刮中获取的数据。它对每个文档都进行了默认加密,从而增加了一层额外的安全性。你可以将 Nokogiri 与 Rails、Sinatra 和 Titanium 等网络框架一起使用。

加油
Cheerio 是 Node.js 数据解析的最佳选择。它提供了一个 API,您可以用它来探索和更改网络扫描结果的数据结构。它不会像浏览器那样进行可视化渲染、应用 CSS 或加载外部资源。与其他框架相比,Cheerio 有很多优势,包括与大多数替代框架相比,它能更好地处理残缺的标记语言,同时还能提供快速的处理速度!

JSoup
JSoup 允许您通过用于检索、提取和操作 URL 的 API 使用 HTML 图形数据。它既可用作浏览器,也可用作网页解析器。尽管通常很难找到其他开源 Java 选项,但它绝对值得考虑。

美丽汤
BeautifulSoup 是一个用于从 HTML 和 XML 文件中提取数据的 Python 库。在解析网络数据时,这个网络爬虫框架非常有用。它与 Django 和 Flask 等 Web 框架兼容。

废料
Scrapy 是一个用 Python 编写的网络爬虫框架,可通过 PyPI 获取。它不仅让编写网络爬虫变得非常简单,同时又足够强大,能够完成自定义任务。Scrapy 也可以作为独立的网络爬取库使用。

Parsimonious
Parsimonious 库使用解析表达式文法(PEG)。您可以在 Python 或 Ruby on Rails 应用程序中使用该解析器。与上下文无关文法相比,PEG 结构简单,因此常被用于某些 Web 框架和解析器中。但在解析某些单词之间没有空格的语言(如 C++ 代码示例)时,PEG 存在局限性。

LXML
Lxml 是另一款 Python XML 解析器,可帮助您遍历网页数据的结构。它还包含许多用于 HTML 解析和 XPath 查询的额外功能,这些功能在抓取网页结果时非常有用。NASA 和 Spotify 的许多项目都曾使用过它,因此其受欢迎程度不言而喻!
在决定哪种方案更适合你的团队之前,你应该从这些方案中得到启发!
防止网络搜索拦截
网络爬虫被封是常见的问题。有些人单纯是不想承受机器人访问带来的流量负担和风险。(讨厌的机器人!)您可以在这里了解更多相关信息。
解决之道是使用轮换的住宅代理。许多网络爬虫 API 都包含此类代理,但如果你打算自行开发解析器,就应该熟悉代理的相关知识。
本文将为您详细介绍住宅代理,以及如何利用它们进行数据提取。
数据解析用例
现在你已经知道了使用解析器将网页转换成易读格式的好处。让我们来看看一些可能对你的团队有帮助的使用案例。

网络安全
您可能希望在通过互联网发送数据文件或将其存储在设备上之前,对数据文件中的任何敏感信息进行加密,以确保数据安全,免受黑客攻击。您可以解析数据日志,扫描恶意软件或其他病毒的踪迹。

网络开发
网络正变得越来越复杂,因此解析数据和使用日志工具来了解用户如何与网页互动非常重要。随着移动应用程序成为我们生活的重要组成部分,网络开发行业将继续增长。

数据提取
数据解析是数据提取的关键做法。网络搜索可能非常耗时,因此必须尽快解析数据,这样才能保证项目按计划进行。对于任何网络开发或数据挖掘项目,你都需要知道如何正确使用数据解析器!

投资分析
投资者可以有效利用数据聚合,从而做出更好的商业决策。投资者、对冲基金或其他评估新创公司、预测盈利甚至控制社会情绪的机构都需要依靠强大的数据提取技术。
网页抓取工具和解析工具使这一过程变得快速高效。它们能优化工作流程,让您将资源调配到其他地方,或专注于更深入的数据分析,例如股票研究和竞争分析。如需了解有关网页抓取工具的更多信息,请点击此处。

登记册分析
注册表分析是检测镜像中恶意软件的一种重要且强大的技术。除了持久化机制外,恶意软件通常还留有其他可供查找的痕迹。这些痕迹包括 MUICache 键下的值、预读取文件、Dr. Watson 数据文件以及其他对象。在某些情况下,这些痕迹以及不同类型的恶意软件能够提供杀毒软件无法检测到的线索。

房地产
解析器可以通过联系方式、物业地址、现金流数据和线索来源为房地产公司带来好处。

财务与会计
数据开发用于分析信用评分和投资组合数据,更好地了解客户与其他用户的互动情况。金融公司在提取数据后使用解析法确定债务偿还率和偿还期。
您还可以将数据解析用于研究目的,以确定利率、贷款支付回报率和银行存款利率。

优化业务工作流程
公司使用数据解析器将非结构化数据分析为有用信息。数据挖掘使公司能够优化工作流程,并利用广泛的数据分析。您可以在广告、社交营销、社交媒体管理和其他业务应用中使用解析。

航运与物流
在网络上提供商品和服务的企业利用数据挖掘来提取账单详细信息。它们使用解析器来排列运输标签,并验证格式是否已更正。

人工智能
自然语言处理(NLP)处于人工智能和机器学习的前沿。它是一种数据解析方法,有助于计算机理解人类语言。
还有更多的用途。随着我们不断进入数字时代,计算机代码和有机数据之间的差别越来越小。
如需了解有关网页抓取和数据解析的更多信息,请访问我们的博客查看更多内容。


