
ETL-Pipelines sind Datenverarbeitungssysteme, die Unternehmen in intelligente, halbautonome Einheiten verwandeln. Dieser Artikel befasst sich eingehend mit ihrem Kern und zeigt Ihnen, wie Sie sie in Ihrem Unternehmen implementieren können.
Der häufigste Anwendungsfall für eine ETL-Pipeline ist das Extrahieren von Daten aus einer Datenbank und deren Übertragung in eine andere Datenbank oder an einen anderen Speicherort im Dateisystem. Es gibt viele Gründe, warum Sie dies tun möchten, doch der häufigste Grund ist, dass Ihre aktuelle Datenbank möglicherweise nicht über ausreichende Kapazität verfügt oder Sie mehr Speicherplatz für Ihre Dateien benötigen.
Doch das ist noch nicht alles.
Die Automatisierung einer ETL-Pipeline löst zahlreiche weitere Probleme, wie beispielsweise die Bereitstellung eines kontinuierlichen Stroms an aufbereiteten Rückmeldungen und Erkenntnissen, die sofort einsatzbereit sind.
Lassen Sie uns etwas genauer hinschauen.
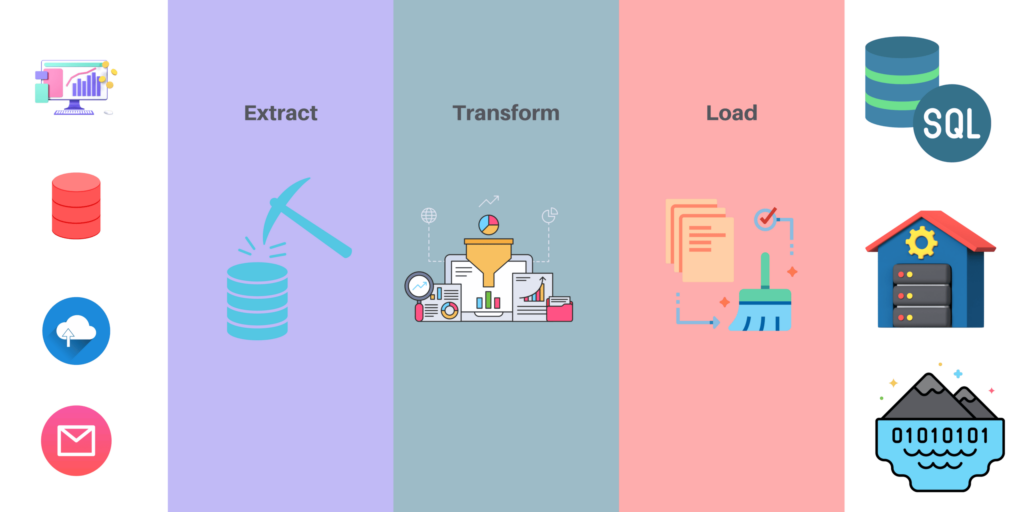
Was sind ETL-Pipelines?
ETL-Pipelines bestehen aus einer Reihe von Tools und Prozessen für die Datenmigration, -transformation, -ladung und -bereinigung. Sie dienen dazu, Daten aus einem Quellsystem in ein Zielsystem zu übertragen.
Die ETL-Pipeline lässt sich in drei Hauptkomponenten unterteilen: Quellsystem, Transformation und Loader.
Das Quellsystemist die Quelle, aus der die Rohdaten stammen. Dabei kann es sich um eine bestehende Datenbank, um Dateien auf der Festplatte usw. handeln. Es enthält alle Daten, die verarbeitet werden müssen. Es kann sich um eine relationale Datenbank, eine Excel-Tabelle oder eine beliebige andere Art von Datenquelle handeln.
Die Transformationist ein Prozess, bei dem Rohdaten so umgewandelt werden, dass sie für andere Systeme wie Datenbanken, Webdienste oder Anwendungen, die vom Quellsystem nicht nativ unterstützt werden, besser nutzbar sind. Mit anderen Worten: Diese Komponente wandelt die Rohdaten aus Ihrer Quelle in ein Format um, das für Ihre Anwendungslogik sinnvoll ist. Wenn Sie beispielsweise Verkaufszahlen verarbeiten und den Gesamtumsatz für jeden Monat berechnen möchten, würden die Rohdaten in diesem Schritt in monatliche Summen umgewandelt.
Loaderist ein Tool, das transformierte Daten in ein Zielsystem wie SQL Server oder Oracle Database lädt, damit diese von anderen Systemen, beispielsweise Berichts- und Business-Intelligence-Tools, weiterverarbeitet werden können.
Darüber hinaus gibt es innerhalb dieser Kernprozesse weitere Schritte.
Lasttransformationen
Diese Transformationen finden nach jeder Transformation statt, um sicherzustellen, dass bei der Verarbeitung keine Fehler auftreten, und um bei der Verarbeitung großer Datenmengen eine bessere Leistung zu erzielen. Sie können sie nutzen, um alle erforderlichen Informationen aus einer Tabelle in eine andere zu laden (z. B. das Laden historischer Datensätze aus einer Tabelle in eine andere).
Ladevorgänge
Diese Vorgänge können tägliche Aktualisierungen an verschiedenen Tabellen innerhalb Ihrer Datenbank vornehmen (z. B. die Aktualisierung von Produktpreisen). Dazu können beispielsweise das Einfügen neuer Zeilen in bestehende Produkttabellen auf der Grundlage der Lagerbestände oder das Löschen alter Zeilen auf der Grundlage ihrer Ablaufdaten usw. gehören. Wenn wir hier von realen Anwendungen sprechen, könnten dies beispielsweise das tägliche Hinzufügen neuer Kunden auf der Grundlage bestimmter, von unseren Geschäftsanwendern festgelegter Kriterien oder das Löschen abgelaufener Kunden sein.
Berichtswesen
Nachdem Sie alle Datenumwandlungen durchgeführt haben, ist es an der Zeit, Berichte zu erstellen. Sie können SQL Server Reporting Services oder Power BI-Berichte nutzen, um sofortiges Feedback darüber zu erhalten, wie gut Ihr ETL-Prozess bisher funktioniert hat.
Welche Vorteile bietet der Einsatz von ETL-Pipelines?
Die Automatisierung Ihrer Datenpipeline bietet zahlreiche Vorteile. Viele davon tragen zu einer gesteigerten Effizienz in der unternehmensinternen Kommunikation und im Feedback bei und unterstützen so intelligente Innovationen.
Spart Zeit und Ressourcen
Der Hauptvorteil der Verwendung einer ETL-Pipeline besteht darin, dass Sie den Prozess automatisieren können, indem Sie Skripte schreiben, die alle Ihre Transformationen an einem Ort durchführen. Dadurch wird sichergestellt, dass Sie in allen Ihren Systemen einheitliche Ergebnisse erhalten, was wiederum bedeutet, dass Sie weniger Zeit für manuelle Aufgaben wie die Erstellung von Berichten mit Excel-Tabellen oder das manuelle Kopieren von Dateien zwischen verschiedenen Anwendungen aufwenden müssen.
Stellen Sie sich vor, die Zeit, die Ihre Mitarbeiter bisher mit der Erfassung und Aufbereitung von Daten verbracht haben, stünde plötzlich zur freien Verfügung. Das bedeutet, dass mühsame und sich wiederholende Aufgaben der Datenerfassung Ihr Team nicht mehr ausbremsen. Dadurch haben Ihre Mitarbeiter mehr Zeit, sich kreativen und leitenden Aufgaben zu widmen.
Reduziert Fehler und sorgt für klarere Erkenntnisse aus den Daten
Zudem erhalten Sie eine deutlich bessere Kontrolle darüber, was mit Ihren Daten geschieht. Sollten beim Transformationsprozess Fehler auftreten, erkennen Sie diese, noch bevor die Daten Ihr System verlassen. Dadurch wird an den Endpunkten Ihrer Daten – dort, wo Ihre Dienstleistungen oder Produkte mit den Kunden in Kontakt treten – deren Feedback berücksichtigt.
Beseitigt Redundanzen
Schließlich läuft alles über ein einziges Skript ab. Das bedeutet, dass Sie sich keine Gedanken darüber machen müssen, dass mehrere Personen gleichzeitig an demselben Bericht arbeiten. Sie schreiben einfach ein Skript und lassen es von allen ausführen.
So integrieren Sie ETL-Pipelines in Ihr Unternehmen.
Viele Unternehmen haben damit begonnen, ETL-Prozesse in ihre Geschäftsabläufe zu integrieren. Die Hauptgründe hierfür sind:
- Die Notwendigkeit der Datenkonsistenz und die Möglichkeit, Informationen aus verschiedenen Quellen in eine einzige Datenbank oder ein einziges System zu überführen.
- Sie können Probleme mit der Datenqualität durch automatisierte Prozesse lösen, die Daten analysieren und entsprechende Berichte erstellen. Dies wird Ihnen dabei helfen, die Leistung Ihres Unternehmens zu verbessern, Kosten zu senken und die Kundenzufriedenheit zu steigern.
- Der Bedarf an präzisen und aktuellen Informationen über Ihre Kunden. Dies wird Ihnen helfen, Ihren Kundenservice zu verbessern, Kosten zu senken und die Kundenzufriedenheit zu steigern. Die Genauigkeit der Daten ist einer der wichtigsten Faktoren, die darüber entscheiden, wie erfolgreich Ihr Unternehmen in Zukunft sein wird.
Doch wie lässt sich die Datenaufbereitung, also eine ETL-Pipeline, in Betrieb nehmen?
Sie können klein anfangen, indem Sie Datensätze von Social-Media-Plattformen wie Facebook oder Reddit sowie von Bewertungsportalen wie Yelp sammeln.
Intern können Sie wichtige Daten aus E-Mails erfassen und diese Informationen nutzen, um Lücken bei Dienstleistungen und Produkten zu identifizieren. Auf dieser Grundlage können Sie eine Prioritätenliste erstellen, anhand derer Sie die entsprechenden Maßnahmen ergreifen können.
In größerem Maßstab ist es möglich, Ihr Unternehmen automatisch mit Daten aus dem gesamten Internet zu versorgen. Diese können Sie dann in lesbare Formate wie PDF-Dateien, Excel-Tabellen oder CSV-Dateien umwandeln.
Weitere Informationen darüber, wo Sie Daten finden können, finden Sie in unserem umfassenden Leitfaden zu Datensätzen. Doch zunächst möchten wir Ihnen die Grundlagen der Datenerfassung mithilfe automatisierter Software-Skripte, sogenannter Web-Scraper, erläutern.
Automatisierung von ETL-Pipelines mithilfe von Web-Scraping-Tools.
Die Automatisierung Ihrer ETL-Pipeline mithilfe von Web-Scraping-Tools ist ein Prozess, der es Ihnen ermöglicht, alle Schritte Ihrer Datenverarbeitungspipeline zu automatisieren.
- Datenerhebung mittels Web-Crawling und Web-Scraping
- Datenbereinigung, beispielsweise das Entfernen von Duplikaten oder fehlerhaften Datensätzen aus Ihrem Datensatz
- Auswerten und Bereinigen von Textdateien
- CSV-Dateien in Datenbanken laden
- Datenvisualisierung, beispielsweise die Erstellung von Balkendiagrammen und Grafiken
Sie können all diese Schritte manuell mit separaten Tools durchführen – dies erfordert jedoch einen hohen Lernaufwand und birgt ein hohes Fehlerrisiko, wenn Sie nicht genau wissen, was Sie tun.
Es gibt Dienste, die Sie in unserer Übersicht über Scraping-Tools entdecken können und die einen Großteil dieses Vorgangs für Sie übernehmen.
Sollten Sie sich für die Nutzung dieser optimierten Dienste entscheiden, empfehlen wir Ihnen, diese mit rotierendenWohn-Proxys zu kombinieren. Kurz gesagt: Sie können die Datenverarbeitung beschleunigen, Ihre Reichweite im Internet vergrößern, Sie vor Datensicherheitslücken schützen und IP-Sperren umgehen.


