
Vous avez du mal à extraire des données sur les produits d'Amazon ? Ce guide vous montre comment rechercher sur Amazon les prix des concurrents, les ASIN et les listes de produits.
Comment obtenir des données sur les produits Amazon.
Vous pouvez obtenir les données sur les produits Amazon en utilisant simplement leur fonction de recherche. Cependant, cela ne sera pas suffisant pour les projets de collecte de données à plus grande échelle qui nécessitent des données en temps réel provenant de plusieurs sites et fiches produits. La seule façon d'y parvenir est d'automatiser le processus à l'aide d'outils de web scraping.
Qu'est-ce que le web scraping ?
Le web scrapingconsiste simplement à collecter des données à partir de pages web et de sites web. Cela implique de programmer des robots pour qu'ils effectuent automatiquement les tâches qu'un humain devrait accomplir pour extraire et organiser ces mêmes données.
Avant d'aller sur Amazon.
Si vous avez un projet de scraping à plus petite échelle, vous pouvez parcourir la liste des catégories de chaque mot-clé. Ensuite, demandez la page du produit pour chacun d'entre eux avant de passer au suivant.
La deuxième option consiste à créer une base de données des produits que vous souhaitez suivre. Pour ce faire, vous avez besoin d'une liste d'ASIN (numéro d'identification standard d'Amazon). Ensuite, à l'aide de votre outil de scraping web, scrapez régulièrement chacune de ces pages individuelles. C'est la méthode la plus courante parmi les scrappeurs qui suivent les produits pour eux-mêmes ou en tant que service.
Mais avant d'en arriver là, comprenons ce qu'est l'ASIN et pourquoi il est essentiel pour collecter des données sur les produits auprès d'Amazon.
Qu'est-ce qu'un ASIN ?
L'ASIN est un code alphanumérique de 10 caractères qui identifie de manière unique chaque produit sur Amazon. Vous trouverez l'ASIN dans les détails techniques ou les informations sur le produit, ainsi que dans l'URL de la page du produit.
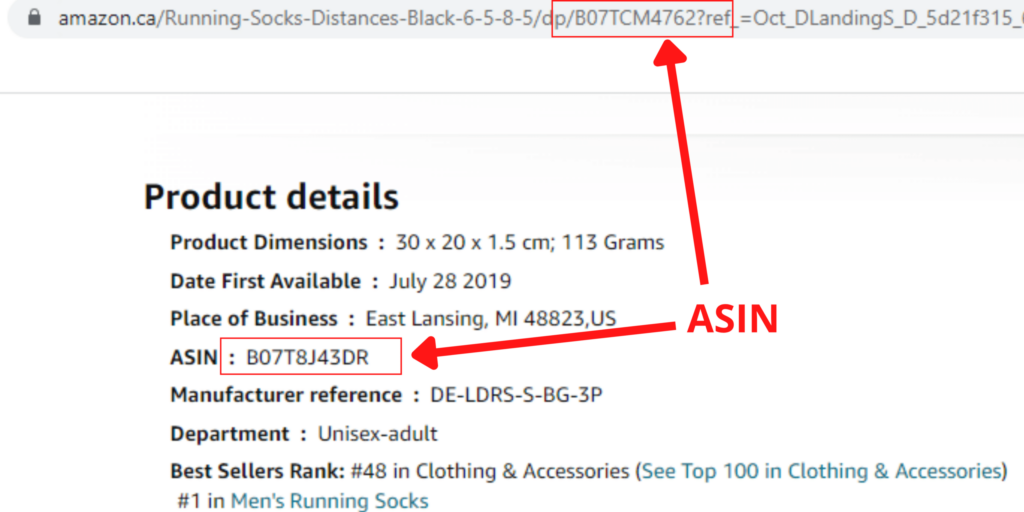
Pourquoi gratter l'ASIN ?
Les ASIN d'Amazon vous permettent d'obtenir des données sur les produits les plus performants, les estimations de ventes quotidiennes et les revenus des produits uniques. Ils permettent également d'identifier les produits similaires ou les concurrents à l'aide de mots-clés et d'informations sur les produits.
Le scraping d'Amazon est-il même légal ?
Il n'existe pas de législation spécifique définissant les limites du web scraping. Cependant, la jurisprudence fait état de nombreuses décisions judiciaires favorables aux poursuivants. Les lois sur la protection de la vie privée s'appliquent lorsque l'on accède sans autorisation à des domaines protégés par un mot de passe. Les dommages matériels constituent des preuves suffisantes pour engager des poursuites contre des pratiques de scraping imprudentes ou mal informées.
En savoir plus surla jurisprudence relative au web scraping.
Trois façons d'exploiter Amazon.
Il existe d'innombrables façons de définir et de catégoriser le web scraping. Les trois approches les plus courantes sont la méthode du copier-coller, l'utilisation de modèles de scraping à source ouverte et les outils de scraping web à service complet.
Méthode du copier-coller
Si vous n'avez besoin que de quelques détails sur un produit Amazon, cette méthode de scraping se passe d'explications. Elle nécessite également peu de temps et de ressources. [Cependant, plus vous avez besoin de données sur les produits, moins la méthode du copier-coller est efficace.
Scripts libres
Supposons que la vue d'un code informatiquenevous fassepasprendre vos jambes à son cou. Dans ce cas, il existe des milliers de scripts gratuits de crawling, de scraping et d'analyse syntaxique disponibles dans des langages de programmation tels que Python, NodeJS, Scrapy, Java, PHP et Ruby. Ces alternatives partagent bon nombre de fonctionnalités communes, mais Python semble disposer des modèles les plus complets pour le web scraping.
API d'extraction de données sur le Web
Les API de scraping web semblent être la solution la plus coûteuse, mais vous devez apprécier la valeur qu'elles apportent à la table. Comme elles sont faciles à mettre en place et à utiliser, elles vous permettent d'économiser le temps nécessaire à l'apprentissage du code, de rationaliser votre processus de collecte de données et de résoudre les problèmes susceptibles de survenir.
L'extraction des données sur les produits Amazon à l'aided'API de web scrapingest simple, car l'interface graphique (GUI) ne nécessite que des actions simples de la part de l'utilisateur, tout en automatisant les tâches de programmation plus fastidieuses en arrière-plan.
Avec la plupart des outils de web scraping comme Octoparse et Parsehub, il suffit de télécharger le logiciel et de suivre un tutoriel rapide pour commencer.
Les avantages du scraping Amazon.
- Suivi des prix en temps réel - Enscrappant perpétuellement Amazon, vous disposez de la ressource la plus récente pour connaître les prix des concurrents. Vous pouvez importer les données recueillies dans une feuille de calcul ou les enregistrer au format JSON.
- Recherche sur le référencement : écoutezles commentaires des consommateurs et les stratégies des concurrents à mesure qu'ils se présentent, ce qui vous permet d'apporter des modifications intelligentes à votre campagne de référencement.
- Données d'évaluation - Optimisez ledéveloppement et la gestion de vos produits, ainsi que le parcours des clients, en récupérant les évaluations de produits à des fins d'analyse.
- Découverte des tendances - Trouver desarticles à fort volume qui n'ont pas suffisamment de produits de qualité pour répondre à la demande.
Les problèmes du web scraping Amazon.
- Un script ne vaut pas pour tous - La plupart desscrappeurs sont préréglés pour naviguer dans une structure de page particulière. S'ils s'écartent de cette structure, ils rencontrent souvent des problèmes. Les pages Amazon sont de toutes les formes et de toutes les tailles et, à bien des égards, elles diffèrent des modèles standard. Si vous faites du scraping avec des scripts open-source, vous devez trouver un code qui tienne compte de ces exceptions.
- Amazon a beaucoup de données - Le fait de récupéreret de stocker des données sur votre système est une bonne chose pour les petits projets. Toutefois, vous finirez par avoir besoin de processeurs très performants et de vastes banques de données pour gérer des volumes croissants. L'utilisation d'un serveur en nuage permet d'éviter de surcharger vos ressources locales et d'optimiser l'ensemble de votre chaîne de collecte de données.
- Amazon surveille l'activité des robots et bannit instantanément les adresses IP.Le scraping webest contraire à la politique d'Amazon, qui l'applique activement. Dès qu'elle vous surprend en train d'envoyer trop de requêtes à partir d'une seule adresse IP - tout en scrappant ses sites - Amazon met votre IP sur liste noire. Son attitude à l'égard de l'activité des robots fait qu'il est difficile de récupérer suffisamment de données pour que cela vaille la peine.
Pourtant, il y a des gens qui grattent Amazon tous les jours. Ceux qui parviennent à contourner les contrôles d'Amazon utilisent des proxys rotatifs.
Comment les procurations résidentielles tournantes peuvent aider.
Grâce à la rotation continue des adresses IP, vos requêtes semblent provenir de milliers de visiteurs uniques, et non d'un seul robot.
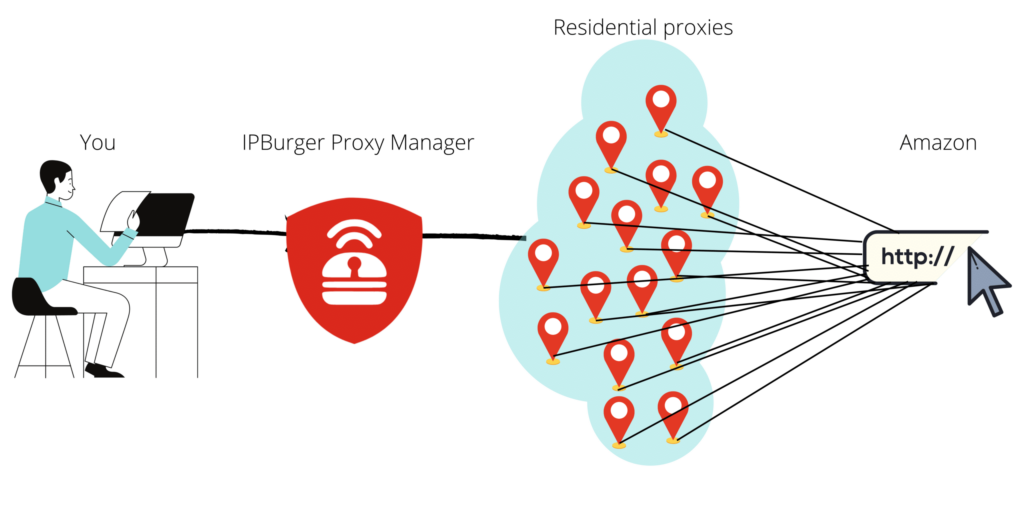
Vous pouvez changer d'adresse IP manuellement, mais cela prend trop de temps. Automatiser ce processus à l'aide d'un outil de gestion de proxys comme le nôtre est bien plus pratique. Combinez cela avec l'accès à plus de 75 millionsde proxys résidentielset vous n'aurez aucun problème pour extraire des données sur Amazon. Téléchargez des listes de proxys provenant de centaines de villes à travers le monde et intégrez-les au logiciel de scraping de votre choix. Vous pouvez également utiliser notre extension de navigateur pour les outils de scraping en ligne.
Prochaines étapes : découvrez-en davantage surles proxys résidentielsetla rotation d'adresses IP.


