
Bạn cảm thấy khó khăn khi lấy dữ liệu sản phẩm từ Amazon? Hướng dẫn này chỉ cho bạn cách thu thập Amazon để biết giá của đối thủ cạnh tranh, ASIN và danh sách sản phẩm.
Cách lấy dữ liệu sản phẩm của Amazon.
Bạn có thể thu thập dữ liệu sản phẩm từ Amazon chỉ bằng cách sử dụng chức năng tìm kiếm của họ. Tuy nhiên, cách này sẽ không hiệu quả đối với các dự án thu thập dữ liệu quy mô lớn hơn, đòi hỏi dữ liệu thời gian thực từ nhiều trang web và danh sách sản phẩm khác nhau. Cách duy nhất để thực hiện điều này là tự động hóa quy trình bằng các công cụ thu thập dữ liệu web.
Web scraping là gì?
Web scrapingđơn giản là việc thu thập dữ liệu từ các trang web và các trang web. Quá trình này bao gồm việc lập trình các bot để tự động thực hiện các tác vụ mà con người thường phải làm để trích xuất và sắp xếp cùng một lượng dữ liệu đó.
Trước khi bạn cạo Amazon.
Nếu bạn có một dự án cạo quy mô nhỏ hơn, bạn có thể thu thập dữ liệu danh sách danh mục của từng từ khóa. Sau đó, yêu cầu trang sản phẩm cho từng trang trước khi chuyển sang trang tiếp theo.
Tùy chọn thứ hai là tạo cơ sở dữ liệu về các sản phẩm bạn muốn theo dõi. Đối với điều này, bạn cần một danh sách ASIN (Số nhận dạng tiêu chuẩn của Amazon). Sau đó, với công cụ quét web của bạn, hãy quét từng trang riêng lẻ này một cách thường xuyên. Đây là phương pháp phổ biến nhất trong số các scraper theo dõi sản phẩm cho chính họ hoặc như một dịch vụ.
Nhưng trước khi đi vào vấn đề đó——chúng ta hãy hiểu ASIN là gì và tại sao nó lại cần thiết để thu thập dữ liệu sản phẩm từ Amazon.
ASIN là gì?
ASIN là mã gồm 10 ký tự chữ và số xác định duy nhất từng sản phẩm trên Amazon. Bạn có thể tìm thấy ASIN trong Chi tiết kỹ thuật hoặc Thông tin sản phẩm của trang thông tin sản phẩm và URL của trang sản phẩm.
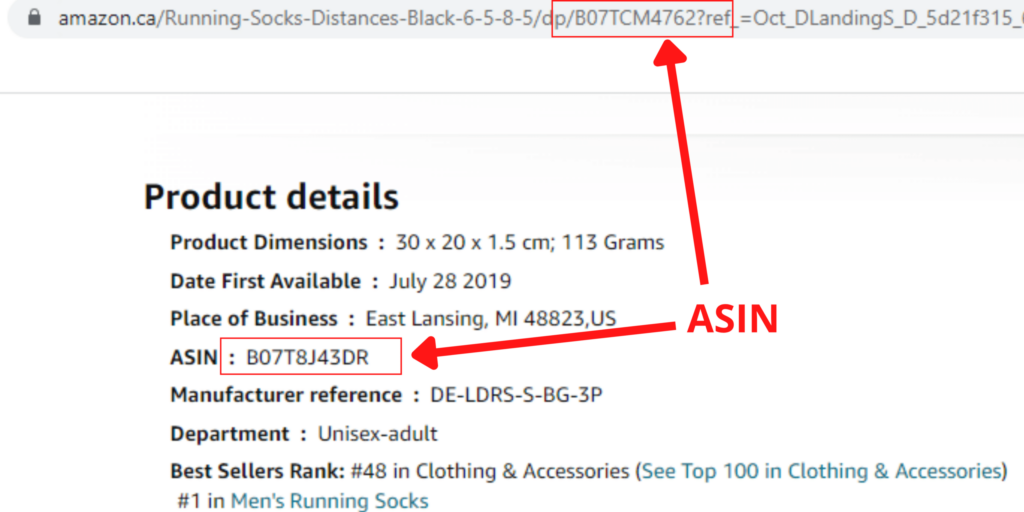
Tại sao phải cạo ASIN?
ASIN từ Amazon giúp bạn lấy dữ liệu từ các sản phẩm hoạt động tốt nhất, ước tính doanh số hàng ngày và doanh thu sản phẩm duy nhất. Họ cũng xác định các sản phẩm tương tự hoặc đối thủ cạnh tranh bằng cách sử dụng từ khóa và thông tin sản phẩm.
Việc cạo Amazon có hợp pháp không?
Hiện chưa có một hệ thống pháp luật riêng biệt nào quy định rõ các giới hạn của việc thu thập dữ liệu trên web. Tuy nhiên, án lệ đã nêu ra rất nhiều phán quyết của tòa án có lợi cho phía công tố. Các quy định về quyền riêng tư sẽ được áp dụng khi bạn xâm nhập trái phép vào các tên miền được bảo vệ bằng mật khẩu. Thiệt hại về tài sản là bằng chứng đủ để khởi kiện đối với các hành vi thu thập dữ liệu thiếu cẩn trọng hoặc thiếu hiểu biết.
Tìm hiểu thêm vềcác tiền lệ pháp lý liên quan đến việc thu thập dữ liệu từ web.
Ba cách để cạo Amazon.
Có vô số cách để xác định và phân loại web scraping. Ba cách tiếp cận phổ biến nhất là phương pháp sao chép-dán, sử dụng các mẫu cạo mã nguồn mở và các công cụ quét web đầy đủ dịch vụ.
Phương pháp sao chép-dán
Nếu bạn chỉ cần thu thập một vài chi tiết sản phẩm ngoài Amazon, phương pháp cạo này là tự giải thích. Nó đòi hỏi ít thời gian hoặc nguồn lực để thực hiện. [chèn hình ảnh] Tuy nhiên, bạn càng cần nhiều dữ liệu sản phẩm, phương pháp sao chép-dán càng trở nên kém hiệu quả.
Tập lệnh mã nguồn mở
Giả sử rằng khi nhìn thấy mã máy tính, bạnkhông vội vàngquay lưng bỏ chạy. Trong trường hợp đó, có hàng nghìn skript miễn phí dành cho việc thu thập dữ liệu, trích xuất và phân tích dữ liệu, được viết bằng các ngôn ngữ lập trình như Python, NodeJS, Scrapy, Java, PHP và Ruby. Các giải pháp này có nhiều tính năng tương đồng, nhưng Python dường như sở hữu bộ mẫu phong phú nhất dành cho việc trích xuất dữ liệu web.
API quét web
API quét web dường như là giải pháp đắt nhất, nhưng bạn phải đánh giá cao giá trị mà chúng mang lại. Vì chúng dễ thiết lập và sử dụng, chúng giúp bạn tiết kiệm thời gian cần thiết để học mã, hợp lý hóa quy trình thu thập dữ liệu và khắc phục sự cố dễ phát sinh.
Việc trích xuất dữ liệu sản phẩm từ Amazon bằngcác API trích xuất dữ liệu webrất đơn giản, bởi vì giao diện người dùng đồ họa (GUI) chỉ yêu cầu người dùng thực hiện các thao tác đơn giản, trong khi các tác vụ lập trình tẻ nhạt hơn ở phía sau được tự động hóa.
Với hầu hết các công cụ quét web như Octoparse và Parsehub, bạn chỉ cần tải xuống phần mềm và làm theo hướng dẫn nhanh để bắt đầu.
Lợi ích của việc cạo Amazon.
- Giám sát giá theo thời gian thực — Bằng cách liên tục cạo Amazon, bạn có tài nguyên cập nhật nhất để định giá đối thủ cạnh tranh. Bạn có thể nhập dữ liệu đã thu thập vào bảng tính hoặc lưu dữ liệu ở định dạng JSON.
- Nghiên cứu SEO — Lắng nghe phản hồi của người tiêu dùng và chiến lược của đối thủ cạnh tranh khi chúng phát sinh, cung cấp cho bạn dữ liệu để thực hiện các thay đổi thông minh cho chiến dịch SEO của bạn.
- Xem lại dữ liệu — Tối ưu hóa quá trình phát triển, quản lý sản phẩm và hành trình của khách hàng bằng cách thu thập các đánh giá sản phẩm để phân tích.
- Khám phá xu hướng — Tìm các mặt hàng có nhiều khối lượng không có đủ sản phẩm chất lượng để đáp ứng nhu cầu.
Các vấn đề với web scraping Amazon.
- Một tập lệnh không quy tắc tất cả chúng — Hầu hết các scraper được đặt trước để điều hướng một cấu trúc trang cụ thể. Nếu có bất kỳ sai lệch nào so với cấu trúc đó, chúng thường gặp vấn đề. Các trang Amazon có đủ hình dạng và kích cỡ – theo nhiều cách, khác với các mẫu tiêu chuẩn. Nếu bạn đang cạo với các tập lệnh nguồn mở, bạn phải tìm mã giải thích cho các ngoại lệ này.
- Amazon có rất nhiều dữ liệu — Cạo và lưu trữ dữ liệu trên hệ thống của bạn là tốt cho các dự án nhỏ. Tuy nhiên, cuối cùng bạn sẽ cần bộ xử lý hiệu suất cao và ngân hàng dữ liệu rộng lớn để xử lý khối lượng ngày càng tăng. Sử dụng máy chủ đám mây ngăn chặn việc đánh thuế quá mức tài nguyên cục bộ của bạn và tối ưu hóa toàn bộ chuỗi thu thập dữ liệu của bạn.
- Amazon giám sát hoạt động của bot và cấm IP ngay lập tức — Việc quét web đi ngược lại chính sách của Amazon và họ tích cực thực thi nó. Ngay khi họ bắt gặp bạn gửi quá nhiều yêu cầu từ một địa chỉ IP duy nhất – trong khi quét các trang web của họ – Amazon đưa IP của bạn vào danh sách đen. Thái độ của họ đối với hoạt động của bot gây khó khăn cho việc thu thập đủ dữ liệu để xứng đáng với thời gian của bạn.
Tuy nhiên, mọi người cạo Amazon mỗi ngày. Những người vượt qua thành công màn hình Amazon sử dụng proxy xoay để làm như vậy.
Làm thế nào luân phiên proxy dân cư có thể giúp đỡ.
Bằng cách liên tục xoay vòng địa chỉ IP, yêu cầu của bạn dường như đến từ hàng ngàn khách truy cập duy nhất – thay vì một bot cạo.
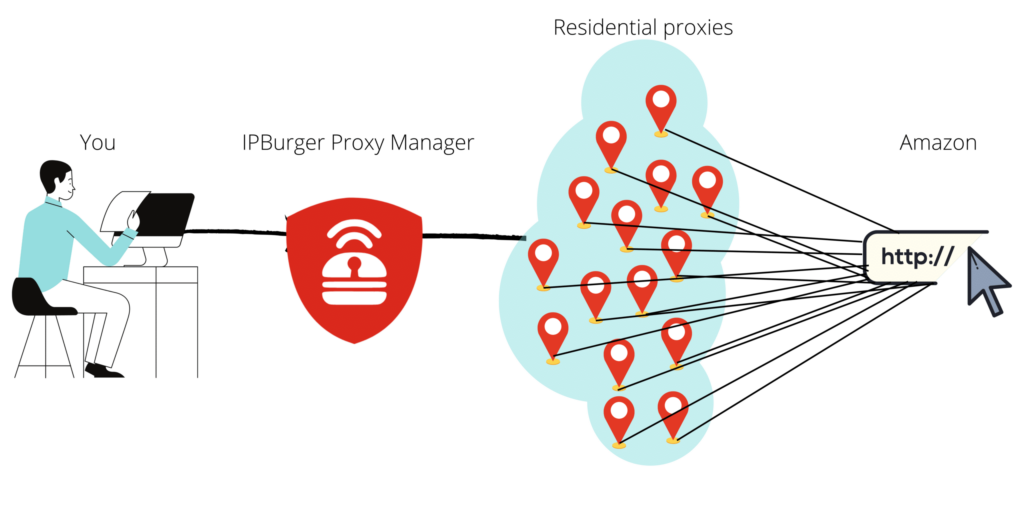
Bạn có thể xoay vòng các địa chỉ IP của mình theo cách thủ công, nhưng việc đó tốn quá nhiều thời gian. Tự động hóa quy trình này bằng một công cụ quản lý proxy như của chúng tôi sẽ thuận tiện hơn rất nhiều. Kết hợp với quyền truy cập vào hơn 75 triệuproxy dân cư, bạn sẽ không gặp bất kỳ vấn đề nào khi thu thập dữ liệu từ Amazon. Tải xuống danh sách các proxy từ hàng trăm thành phố trên toàn thế giới và tích hợp chúng vào phần mềm thu thập dữ liệu web mà bạn lựa chọn. Hoặc bạn có thể sử dụng tiện ích mở rộng trình duyệt của chúng tôi dành cho các công cụ thu thập dữ liệu trực tuyến.
Các bước tiếp theo: Tìm hiểu thêm vềproxy dân dụngvà tínhnăng xoay vòng địa chỉ IP.


