
Web-Scraper spucken etwas aus, das wie halbverdaute Buchstabensuppe aussieht.
Eklig.
Man könnte auf Magen-Darm-Beschwerden schließen, aber das trifft es nicht ganz.
Web-Scraper verarbeiten Daten in einem unstrukturierten Format, sodass Sie am Ende ein HTML-Dokument oder ein ähnliches Durcheinander erhalten.
Hier kommt die Datenauswertung ins Spiel.
Die Datenauswertung ist eine Methode, mit der Web-Scraper Webseiten in ein besser lesbares Format umwandeln. Dies ist ein wesentlicher Schritt beim Web-Scraping, da die Daten andernfalls nur schwer zu lesen und zu analysieren wären.
Das Parsen ist für das Lesen von Computersprachen unerlässlich. Wie Sie bald sehen werden, ist es auch für das Verständnis der Realität von entscheidender Bedeutung.
Definition von „Parsing“
Der Begriff „[Daten]-Parsing“ leitet sich vom lateinischen Wort „pars (orationis)“ ab, was „Wortart“ bedeutet. Er kann in verschiedenen Bereichen der Sprachwissenschaft und Informatik leicht unterschiedliche Bedeutungen haben.
In der Psycholinguistik wird der Begriff verwendet, um zu erörtern, welche mündlichen Hinweise einem Sprecher dabei helfen, „Garden-Path“-Sätze zu interpretieren. In einer anderen Sprache kann der Begriff „Parsing“ auch eine Aufteilung oder Trennung bedeuten.
Wow, das ist mehr, als Sie wissen möchten, nicht wahr?
Damit möchte ich sagen, dass „parse“ bedeutet, Sprache in Teile zu zerlegen.
Nehmen wir einmal an, wir definieren das Parsen in der Sprache der Computerprogrammierung. (Habe ich nun Ihr Interesse geweckt?)
In diesem Fall beziehen Sie sich darauf, wie Sie eine Zeichenfolge – einschließlich Sonderzeichen – lesen und verarbeiten, um besser zu verstehen, was Sie erreichen möchten.
Der Begriff „Parsing“ wird von Linguisten und Programmierern unterschiedlich definiert. Dennoch herrscht allgemein Einigkeit darüber, dass er die Analyse von Sätzen und die Ermittlung semantischer Beziehungen zwischen diesen bezeichnet. Mit anderen Worten: Parsing ist das Filtern und Ordnen von Datenstrukturen.
Was versteht man unter Datenauswertung?
Der Begriff „Datenparsing“ bezeichnet die Verarbeitung unstrukturierter Daten und deren Umwandlung in ein neues, strukturiertes Format.
Der Prozess der Datenauswertung findet überall statt. Ihr Gehirn wertet ständig Daten aus Ihrem Nervensystem aus.
Doch anstatt dass DNA-Programme Schmerz und Freude analysieren, um die Entstehung von Leben zu fördern – im Kontext dieses Artikels wandeln diese „Parser“ die aus Web-Scraping-Ergebnissen gewonnenen Daten um.
(Enttäuschung)
In beiden Fällen müssen wir jedoch ein Datenformat so anpassen, dass es in einer verständlichen Form vorliegt. Sei es nun die Erstellung von Berichten aus HTML-Zeichenketten oderdas Sensorgating.
Der Aufbau eines Datenparsers
Die Datenauswertung umfasst in der Regel zwei wesentliche Phasen: die lexikalische Analyse und die syntaktische Analyse. Diese Schritte wandeln eine Zeichenfolge unstrukturierter Daten in einen Datenbaum um, dessen Regeln und Syntax in die Struktur des Baums integriert sind.
Lexikalische Analyse
Bei der lexikalischen Analyse in ihrer einfachsten Form wird jedem Datenelement ein Token zugewiesen. Zu den Tokens oder lexikalischen Einheiten gehören Schlüsselwörter, Trennzeichen und andere Bezeichner.
Nehmen wir einmal an, Sie haben eine lange Reihe von Kreaturen, die an Bord eines Schiffes gehen. Wenn sie das Tor passieren, erhält jede Kreatur einen Spielstein. Der Elefant erhält den „Spielstein für riesige Landtiere“ und der Alligator den „Spielstein für gefährliche Amphibien“.

Dann wissen wir, wo wir jedes Lebewesen auf dem Schiff unterbringen müssen, damit niemand während des Sonnenkreuzfahrturlaubs zu Schaden kommt.
In der Welt der Datenauswertung werden unstrukturierten Daten lexikalische Einheiten zugeordnet. So erhält beispielsweise ein Wort in einer HTML-Zeichenkette ein Wort-Token und so weiter. Zu den irrelevanten Token gehören Elemente wie Klammern, geschweifte Klammern und Semikolons. Anschließend können Sie die Daten nach Token-Typ sortieren.
Wie Sie sehen können, ist die lexikalische Analyse ein entscheidender Schritt, um genaue Daten für die syntaktische Analyse zu liefern.
Und die Alligatoren in Schach zu halten.
Syntaktische Analyse
Die Syntaxanalyse ist der Vorgang der Erstellung eines Parsebaums. Wenn Sie mit HTML vertraut sind, wird Ihnen dies leicht verständlich sein. Nehmen wir beispielsweise an, wir analysieren eine HTML-Webseite und erstellen ein Document Object Model (DOM). Der Text zwischen den Tags wird zu untergeordneten Knoten oder Zweigen im Parsebaum, während die Attribute zu Zweigeigenschaften werden.
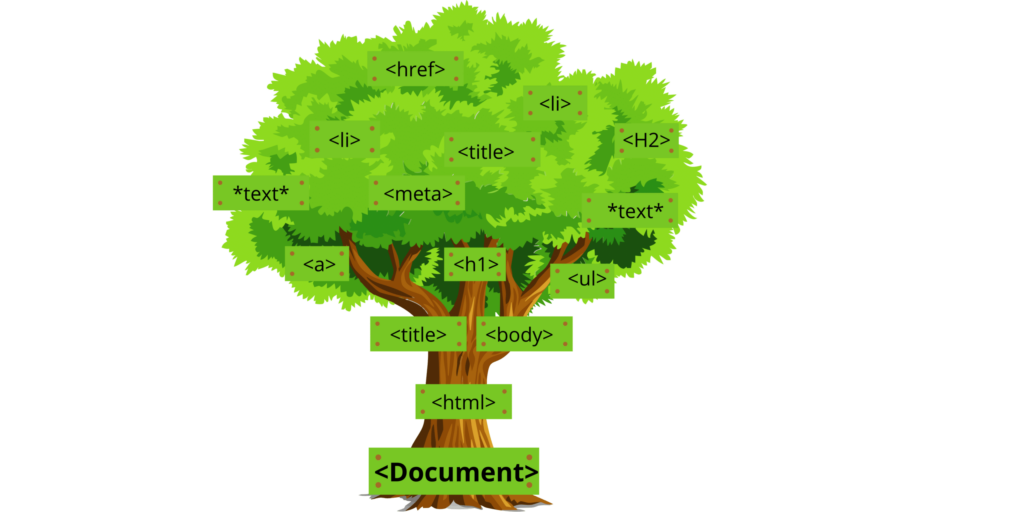
In der Phase der syntaktischen Analyse werden Datenstrukturen erstellt, die den bisher bloßen Rohdaten in Form von Zeichenfolgen einen Sinn verleihen. In dieser Phase werden zudem alle Token nach Typ gruppiert – entweder Schlüsselwörter oder Bezeichner wie Klammern, geschweifte Klammern usw. Somit verfügt jedes Token über einen eigenen Knoten innerhalb der übergeordneten Struktur, die von Ihrem Parser-Tool aufgebaut wird.
Semantische Analyse
Die semantische Analyse ist ein Schritt, der in den meisten Web-Scraping-Tools nicht implementiert ist. Sie ermöglicht es Ihnen, Daten aus HTML-Code zu extrahieren, indem verschiedene Wortarten wie Substantive, Verben und andere Funktionen innerhalb von Sätzen identifiziert werden.
Doch kehren wir für diese Erörterung der semantischen Analyse zur Analyse unserer Webseite anhand von Syntaxregeln zurück. Der Parser zerlegt jeden Satz in seine korrekte Form. Anschließend fährt er fort, Knoten zu bilden, bis er auf das End-Tag oder die schließende geschweifte Klammer „}“ stößt – was das Ende eines Elements kennzeichnet.
Der Parsebaum würde Ihnen zeigen, welche Elemente eine Rolle spielen – beispielsweise, aus welchen Wörtern sich der Inhalt Ihrer Webseite zusammensetzt –, jedoch nichts über die Interpretation (Semantik), da während der syntaktischen Analyse keine Werte zugewiesen wurden. Dazu müssen Sie zurückgehen und die Elemente der Webseite erneut analysieren.
Arten von Datenparsern
Top-down- und Bottom-up-Parser sind zwei unterschiedliche Strategien zur Datenanalyse.
Das Top-Down-Parsingist eine Methode zum Verständnis von Sätzen, bei der man zunächst die kleinsten Bestandteile betrachtet und sich dann nach oben vorarbeitet. Dies wird als „Ursuppen-Ansatz“ bezeichnet. Es ähnelt stark der Satzanalyse, bei der die Bestandteile eines Satzes zerlegt werden. Eine Variante dieser Art von Parsern sind LL-Parser.
Die Bottom-up-Analysebeginnt am Ende und arbeitet sich nach oben vor, wobei zunächst die grundlegendsten Teile ermittelt werden. Eine Variante dieser Art von Parsern sind die sogenannten LR-Parser.
Selber bauen oder kaufen?
Ähnlich wie beim Kochen von Makkaroni mit Käse ist es manchmal günstiger, das Gericht selbst zuzubereiten, anstatt das fertige Produkt zu kaufen. Bei Datenparsern ist diese Frage nicht so einfach zu beantworten. Bei der Entscheidung, ob man Tools zur Datenextraktion selbst entwickelt oder kauft, sind weitere Aspekte zu berücksichtigen. Betrachten wir das Potenzial und die Ergebnisse beider Optionen, wobei beide Möglichkeiten zur Verfügung stehen.

Kauf eines Datenparsers
Im Internet gibt es eine Vielzahl von Parsing-Technologien. Sie können einen Parser erwerben und erhalten so schnell und zu einem erschwinglichen Preis Ergebnisse. Der Nachteil dieses Ansatzes besteht darin, dass Sie mehr als ein Produkt erwerben müssen, wenn Ihre Software auf verschiedenen Plattformen oder für andere Zwecke eingesetzt werden soll.
Dies kann mit der Zeit kostspielig werden und ist je nach den Zielen und Ressourcen Ihres Teams möglicherweise nicht praktikabel. Es stehen sowohl kostenlose als auch kostenpflichtige Tools zur Datenauswertung zur Verfügung. Letztendlich hängt jedoch alles davon ab, was Ihr Team benötigt. Berücksichtigen Sie dies daher, wenn Sie den Kauf eines Webdienstes in Erwägung ziehen, anstatt selbst maßgeschneiderten Code zu entwickeln.
Vorteile des Outsourcings
- Mit dem Erwerb eines Datenparsers erhalten Sie Zugang zu Parsing-Technologien eines auf Datenextraktion spezialisierten Unternehmens. Ein Großteil der Ressourcen dieses Unternehmens fließt in die Weiterentwicklung und Optimierung des Daten-Parsings.
- Ihnen stehen mehr Zeit und Ressourcen zur Verfügung, da Sie weder in ein Team investieren noch Zeit für die Wartung Ihres eigenen Parsers aufwenden müssen. Die Wahrscheinlichkeit, dass Probleme auftreten, ist geringer.
Nachteile des Outsourcings
- Wahrscheinlich werden Sie nicht genügend Möglichkeiten haben, Ihren Datenparser an Ihre geschäftlichen Anforderungen anzupassen.
- Wenn Sie die Programmierung auslagern, können Kosten für etwaige Anpassungen anfallen.
Erstellung eines Datenparsers
Die Entwicklung eines eigenen Datenparsers ist zwar vorteilhaft, kann jedoch zu viel Energie und Ressourcen beanspruchen. Dies gilt insbesondere dann, wenn Sie einen komplexen Datenparsing-Prozess benötigen, um große Datenstrukturen zu analysieren. Die Entwicklung und Wartung erfordern ein kompetentes und erfahrenes Entwicklungsteam. Soweit ich weiß, sind Datenwissenschaftler nicht gerade billig!

Die Entwicklung eines Datenparsers erfordert unter anderem folgende Fähigkeiten:
- Verarbeitung natürlicher Sprache
- Datenauswertung
- Webentwicklung
- Erstellung eines Parsebaums
Sie oder Ihr Team müssen über fundierte Kenntnisse in Programmiersprachen und Parsing-Technologien verfügen.
Eigene Fachkräfte
- Interne Parser sind effektiv, da sie anpassbar sind.
- Wenn Sie Ihren Datenparser intern entwickeln, haben Sie die vollständige Kontrolle über Wartung und Aktualisierungen.
- Wenn die Datenauswertung ein wesentlicher Bestandteil Ihres Geschäfts ist, wird dies langfristig kosteneffizienter sein.
Außerdem profitieren Sie davon, dass Sie Ihr eigenes Produkt nach der Entwicklung überall einsetzen können – was bei der Entwicklung eigener Datenparser im Gegensatz zum Kauf eines solchen unverzichtbar ist. Wenn Sie einen Parser kaufen, sind Sie an die jeweilige Plattform gebunden, wie beispielsweise Google Sheets.
Interne Nachteile
- Die Pflege, Aktualisierung oder das Testen eines eigenen Parsers ist zeitaufwendig. So benötigen Sie beispielsweise für die Bearbeitung und das Testen Ihres eigenen Parsers einen Server, der die erforderlichen Ressourcen bereitstellen kann.
Welche Tools benötigen Sie für die Datenauswertung?

Wenn Sie einen Web-Scraper entwickeln möchten, benötigen Sie eine Bibliothek zur Datenauswertung in der entsprechenden Programmiersprache. Ruby, Python, JavaScript (Node.js), Java und C++ stehen zur Auswahl, je nachdem, welche Programmiersprache Sie für Ihr Datenauswertungsprojekt verwenden möchten.
Diese Programmiersprachen lassen sich mit dem Web-Crawling-Framework Nokogiri oder – im Falle von Python – mit Web-Frameworks wie Django oder Flask kombinieren.
Oder, falls Sie sich für Ruby entscheiden, können Sie zwischen Nokigiri und Cheerio wählen, wobei Cheerio eine API bereitstellt, die sich gut in Rails-Webanwendungen integrieren lässt.
Für die Programmierung mit Node.js kann JSoup verwendet werden, während Scrapy auch hier eine weitere Option für das Web-Crawling darstellt!
Schauen wir uns das einmal genauer an:

Nokogiri
Mit Nokogiri können Sie in Ruby mit HTML arbeiten. Es verfügt über eine API, die den Paketen anderer Programmiersprachen ähnelt und es Ihnen ermöglicht, die durch Web-Scraping gewonnenen Daten abzufragen. Jedes Dokument wird standardmäßig verschlüsselt, was für zusätzliche Sicherheit sorgt. Sie können Nokogiri mit Web-Frameworks wie Rails, Sinatra und Titanium verwenden.

Bis bald
Cheerio ist eine hervorragende Wahl für die Datenauswertung in Node.js. Es bietet eine API, mit der Sie die Datenstruktur Ihrer Web-Scraping-Ergebnisse untersuchen und ändern können. Es verfügt jedoch nicht über eine visuelle Darstellung, wendet kein CSS an und lädt keine externen Ressourcen, wie es ein Browser tun würde. Cheerio hat gegenüber anderen Frameworks zahlreiche Vorteile, darunter einen besseren Umgang mit fehlerhaften Markup-Sprachen als die meisten Alternativen bei gleichzeitig hoher Verarbeitungsgeschwindigkeit!

JSoup
Mit JSoup können Sie HTML-Daten über eine API zum Abrufen, Extrahieren und Bearbeiten von URLs nutzen. Die Bibliothek fungiert sowohl als Browser als auch als Parser für Webseiten. Auch wenn es oft schwierig ist, andere Open-Source-Optionen für Java zu finden, ist diese Bibliothek auf jeden Fall eine Überlegung wert.

BeautifulSoup
BeautifulSoup ist eine Python-Bibliothek zum Extrahieren von Daten aus HTML- und XML-Dateien. Dieses Web-Crawling-Framework ist äußerst hilfreich, wenn es um die Auswertung von Webdaten geht. Es ist mit Web-Frameworks wie Django und Flask kompatibel.

Scrapy
Scrapy ist ein in Python geschriebenes Web-Crawling-Framework, das über PyPI verfügbar ist. Es erleichtert das Erstellen von Web-Crawlern erheblich und ist gleichzeitig leistungsstark genug, um individuelle Aufgaben zu bewältigen. Scrapy kann auch als eigenständige Web-Scraping-Bibliothek verwendet werden.

Sparsam
Die Parsimonious-Bibliothek nutzt die Parsing-Expression-Grammatik (PEG). Sie können diesen Parser in Python- oder Ruby-on-Rails-Anwendungen verwenden. PEGs kommen aufgrund ihrer Einfachheit im Vergleich zu kontextfreien Grammatiken häufig in einigen Web-Frameworks und Parsern zum Einsatz. Sie weisen jedoch Einschränkungen auf, wenn es darum geht, Sprachen zu analysieren, in denen zwischen einigen Wörtern keine Leerzeichen stehen, wie beispielsweise bei C++-Code-Beispielen.

LXML
Lxml ist ein weiterer Python-XML-Parser, mit dem Sie die Struktur von Daten aus Webseiten durchlaufen können. Er bietet zudem zahlreiche Zusatzfunktionen für das Parsen von HTML und XPath-Abfragen, die beim Scraping von Webinhalten hilfreich sein können. Er wurde bereits in vielen Projekten der NASA und von Spotify eingesetzt, sodass seine Beliebtheit zweifellos für sich spricht!
Lassen Sie sich von diesen Optionen inspirieren, bevor Sie entscheiden, welche für Ihr Team am besten geeignet ist!
Verhindern von Web-Scraping-Sperren
Es kommt häufig vor, dass Web-Scraping blockiert wird. Manche möchten einfach nicht die Belastung und das Risiko in Kauf nehmen, die mit Bot-Besuchern einhergehen. (Lästige Bots!) Hier erfahren Sie mehr darüber.
Der richtige Weg ist der Einsatz von rotierenden Residential-Proxys. Viele Web-Scraping-APIs enthalten diese bereits, doch sollten Sie sich mit Proxys auskennen, wenn Sie vorhaben, einen eigenen Parser zu entwickeln.
In diesem Artikel erfahren Sie alles über Residential-Proxys und wie Sie diese für die Datenextraktion nutzen können.
Anwendungsfälle für die Datenauswertung
Nun kennen Sie die Vorteile der Verwendung eines Parsers, um Webseiten in ein leicht lesbares Format umzuwandeln. Sehen wir uns einige Anwendungsfälle an, die Ihrem Team helfen könnten.

Websicherheit
Möglicherweise möchten Sie Ihre Daten vor Hackern schützen, indem Sie alle sensiblen Informationen in Ihren Datendateien verschlüsseln, bevor Sie diese über das Internet versenden oder auf Geräten speichern. Sie können Datenprotokolle auswerten und nach Spuren von Malware oder anderen Viren suchen.

Webentwicklung
Das Internet wird immer komplexer, daher ist es wichtig, Daten auszuwerten und Protokollierungstools zu nutzen, um zu verstehen, wie Nutzer mit Webseiten interagieren. Die Webentwicklungsbranche wird weiter wachsen, da mobile Apps zunehmend einen großen Teil unseres Lebens einnehmen.

Datenextraktion
Die Datenauswertung ist ein entscheidender Schritt bei der Datenextraktion. Das Web-Scraping kann sehr zeitaufwendig sein, und es ist wichtig, die Daten so schnell wie möglich auszuwerten, damit Ihr Projekt im Zeitplan bleibt. Für alle Webentwicklungs- oder Data-Mining-Projekte müssen Sie wissen, wie man einen Datenparser richtig einsetzt!

Anlagenanalyse
Anleger können die Datenaggregation effizient nutzen, um fundiertere Geschäftsentscheidungen zu treffen. Anleger, Hedgefonds und andere Akteure, die Start-up-Unternehmen bewerten, Gewinne prognostizieren und sogar die Stimmung in den sozialen Medien analysieren, stützen sich auf zuverlässige Techniken zur Datenextraktion.
Web-Scraper und Parsing-Tools sorgen für eine schnelle und effiziente Bearbeitung. Sie optimieren den Arbeitsablauf und ermöglichen es Ihnen, Ressourcen anderweitig einzusetzen oder sich auf tiefgreifendere Datenanalysen wie Aktienresearch und Wettbewerbsanalysen zu konzentrieren. Weitere Informationen zu Web-Scraping-Toolsfinden Sie hier.

Registry-Analyse
Die Registrierungsanalyse ist eine wichtige und leistungsstarke Methode zur Suche nach Malware in einem Image. Neben Persistenzmechanismen weist Malware häufig weitere Artefakte auf, nach denen Sie suchen können. Zu diesen Artefakten zählen Werte unter dem Schlüssel „MUICache“, Prefetch-Dateien, die Dr. Watson-Datendateien sowie weitere Objekte. Diese sowie verschiedene Arten von Malware können in solchen Fällen Hinweise liefern, die Antivirenprogramme nicht erkennen können.

Immobilien
Ein Parser kann einem Immobilienunternehmen durch Kontaktdaten, Immobilienadressen, Cashflow-Daten und Lead-Quellen von Nutzen sein.

Finanzen und Rechnungswesen
Die Datenauswertung dient dazu, Daten zu Bonitätsbewertungen und Anlageportfolios zu analysieren und bessere Einblicke in die Interaktionen der Kunden mit anderen Nutzern zu gewinnen. Finanzunternehmen nutzen die Datenauswertung, um nach der Extraktion der Daten den Zinssatz und die Laufzeit der Schuldentilgung festzulegen.
Sie können die Datenauswertung auch zu Forschungszwecken nutzen, um Zinssätze, die Rückzahlungsquote von Krediten und die Verzinsung von Bankeinlagen zu ermitteln.

Optimierung von Geschäftsabläufen
Datenparser werden von Unternehmen eingesetzt, um unstrukturierte Daten in nützliche Informationen umzuwandeln. Mithilfe von Data Mining können Unternehmen ihre Arbeitsabläufe optimieren und von umfassenden Datenanalysen profitieren. Sie können das Parsing in den Bereichen Werbung, Social-Media-Marketing, Social-Media-Management und anderen geschäftlichen Anwendungsbereichen nutzen.

Versand und Logistik
Unternehmen, die Waren und Dienstleistungen im Internet anbieten, nutzen Data Scraping, um Rechnungsdaten zu extrahieren. Sie verwenden Parser, um Versandetiketten zu erstellen und zu überprüfen, ob die Formatierung korrekt ist.

Künstliche Intelligenz
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) steht an vorderster Front der künstlichen Intelligenz und des maschinellen Lernens. Es handelt sich um einen Ansatz der Datenanalyse, der Computern dabei hilft, die menschliche Sprache zu verstehen.
Es gibt noch so viele weitere Anwendungsmöglichkeiten. Je weiter wir uns im digitalen Zeitalter voranschreiten, desto geringer wird der Unterschied zwischen Computercode und organischen Daten.
Weitere Informationen zum Thema Web-Scraping und Datenauswertung finden Sie in weiteren Beiträgen unseres Blogs.


