
欢迎来到机器学习和网络搜索 API 的世界!随着数字技术的兴起,这两种强大的工具在商业世界中的作用越来越大。
本文将探讨机器学习和网络搜索 API 的基础知识,以及它们对企业的重要性。请戴上思考帽,进入数据驱动决策的奇妙世界!
机器学习和网络抓取应用程序接口的定义
机器学习是人工智能(AI)的一种,它允许计算机在没有明确编程的情况下进行学习。它的重点是开发能够访问数据并利用数据进行自我学习的计算机程序。
所以,我们应该对我们的电子产品好一点。以防万一。
网络搜索是从网站中提取数据的过程。它包括使用程序自动从网站获取信息,并以结构化的方式进行存储。
Web scraping API 是应用程序编程接口(API),允许开发人员以自动方式从网站中提取数据。这些 API 通常用于从网页中提取结构化数据,并以更简便的格式提供给用户使用和操作。网络搜刮 API 可以从各种网络来源收集信息,如在线评论、新闻文章、社交媒体帖子和网页。从网络搜刮 API 收集到的数据可用于多种应用,包括情感分析、趋势分析和个性化。
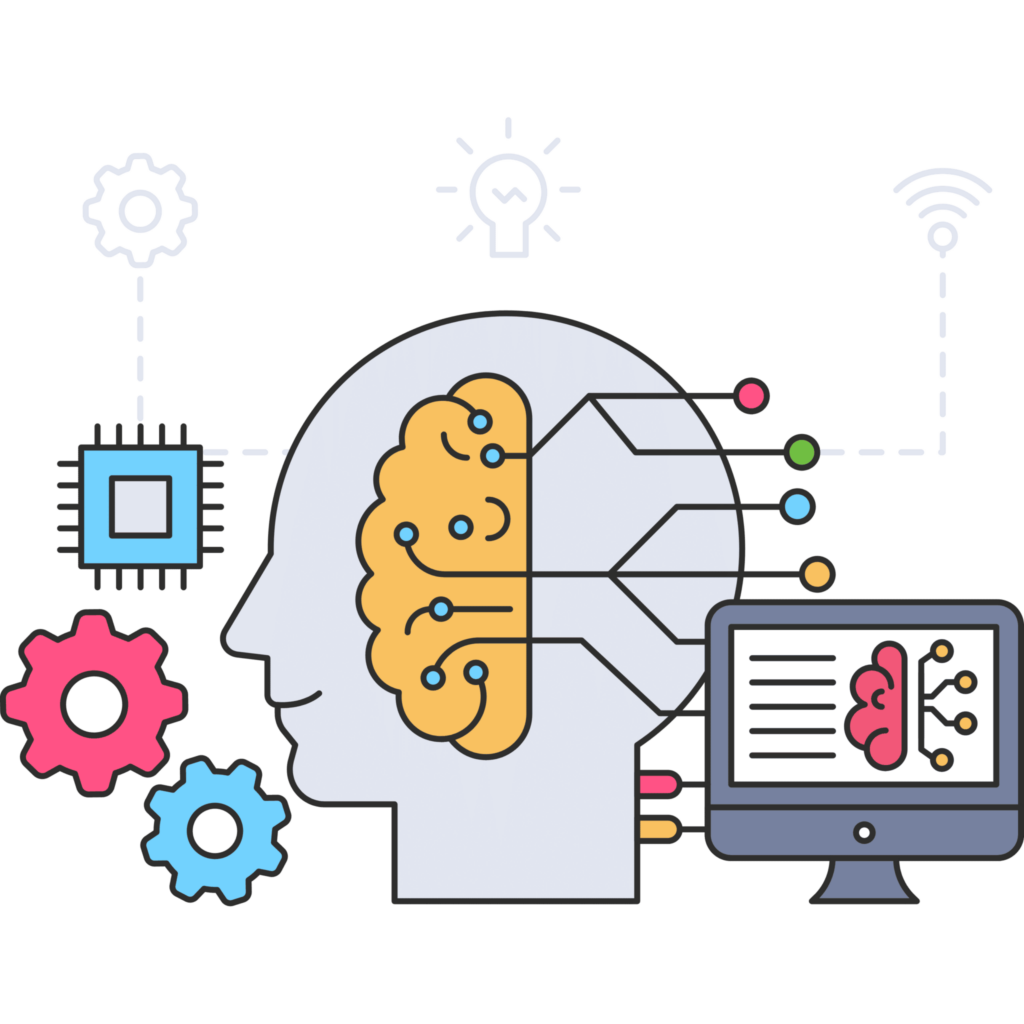
机器学习与网络搜索应用程序接口之间的关系
网络搜刮应用程序接口可以从网络上收集大量数据,然后用于训练有监督和无监督的机器学习算法。
For example, web scraping APIs can be used to collect text, images, audio, and video from various sources on the web, which can then be used to train natural language processing (NLP) algorithms.
网络搜刮应用程序接口还可以从社交媒体网站获取信息,用于训练分析人们情感的算法。(祝你好运)
简而言之,网络刮擦可以自动进行机器学习,从而让人工智能能够为自己提供信息。
利用机器学习和网络抓取 API 的好处
机器学习和网络刮擦使数据收集和分析变得更容易、更快捷。
通过使用自动算法和流程来收集、组织和分析数据,企业可以节省时间和金钱。
机器学习和网络搜刮也能提高所收集数据的质量,因为它们能从许多不同的来源找到并提取相关数据。
最后,机器学习和网络搜索使企业从各种来源获取信息成为可能。通过访问各种来源的数据,企业可以深入了解各种市场和行业,从而做出更明智的决策。
让我们来详细了解一下机器学习和网络扫描应用程序接口的优势:
- 降低成本:与手动收集数据相比,自动网络搜索更具成本效益。
- 改进决策:机器学习算法有助于根据收集到的数据做出更好的决策。
- 自动个性化:机器学习算法可根据用户过去的行为帮助个性化用户体验。
- 改进分析: 机器学习算法有助于发现人工无法发现的数据趋势和模式。
- 提高准确性和效率: 通过使用机器学习算法,Web scraping API 可以更快、更准确地从网站上获取数据。然后,这些信息可用于建立预测未来的模型、分析客户数据,甚至自动执行价格比较等任务。
- 自动数据收集:网络刮擦应用程序接口可用于自动收集数据
- 更好的安全性: Web scraping API 可通过机器学习算法发现网页中的恶意内容。这有助于保护企业免受安全威胁。
- 更好的数据分析: Web scraping API 可帮助企业使用机器学习算法更好地分析数据。这样就能获得更深入的见解。这可以帮助企业做出更好的决策、优化运营并保持竞争力。
如何利用机器学习和网络抓取 API
步骤 1:确定所需的数据
要使用机器学习和网络搜索,第一步是找到你想要的数据。在这一步中,您要定义机器学习算法使用的数据,并选择数据的来源。
步骤 2:收集和清理数据
在确定需要哪些数据后,下一步就是收集和清理数据。清理数据可能涉及一些简单的工作,如消除重复数据或将数据转换成机器学习算法可以使用的格式。
步骤 3:设置机器学习算法
收集和准备好数据后,就该设置用于处理和分析数据的机器学习算法了。这就需要选择正确的算法并对其进行设置,使其能够与数据协同工作,并给出所需的结果。
算法设置完成后,对其进行测试并确保其正常运行非常重要。这可以通过运行小型测试和评估结果来实现。如果发现任何问题,应先处理并解决这些问题,然后再进行全面分析。
一旦算法正常运行,就可以用它来处理和分析收集到的数据。您可能需要采取额外的步骤,以合理的方式解释和呈现结果,这取决于您希望发生什么。
步骤 4:执行机器学习算法
- 选择合适的 ML 算法。 根据任务的难度和数据量的多少,不同的算法可能会有更好的效果。选择算法时要考虑准确性、速度、可扩展性和可解释性等因素。
- 收集和准备训练数据。这可能需要对数据进行清理、规范化、转换和标记。
- 训练模型。 这意味着将训练数据输入模型,并调整参数以获得最佳结果。
- 测试模型。 检查模型在其尚未看到的数据上的运行情况,并确保其足够准确。
- 部署模型。将模型集成到应用程序中,并在实际场景中监控其性能。
- 监控模型。 监控模型的性能,寻找退化或漂移的迹象。根据需要重新训练或调整参数。
利用机器学习和网络抓取 API 的挑战

实施成本
实施机器学习和网络搜索的成本可能相当高。根据项目范围和所需资源的不同,成本从几百到几万不等。此外,系统需要由具备适当技能和培训的人员来制作和维护。这会进一步增加实施成本。

技术挑战
利用机器学习和网络搜索会面临一些技术挑战。其中包括收集和准备数据、设计特征、选择和训练模型以及使用模型。
此外,还需要制定算法,以便快速处理大型数据集,发现并解决数据泄漏、过度拟合和偏差等问题。

隐私与安全问题
机器学习和网络搜刮的最大问题之一是可能导致隐私和安全问题。当有人刮擦一个网站时,他们可以获得敏感的个人信息,如姓名、地址和财务信息。这些信息可以用来找出某人的身份。此外,坏人还可以利用机器学习算法获取信用卡号和密码等私人信息。
准确性和可靠性
在使用机器学习和网络搜索时,确保收集到的数据准确可靠也很重要。网络搜索可能会出错,因为收集到的数据可能需要补全,也可能是错误的。此外,机器学习算法也可能出错,因为用于训练算法的数据可能会给算法带来偏差。因此,必须确保用于网络搜刮和机器学习的数据和算法是好的。

监管合规
最后,必须从法律和监管的角度考虑使用机器学习和网络搜索的意义。在收集和使用数据时,企业必须确保符合相关的数据保护法律,如 GDPR 和 CCPA。
此外,组织还必须确保不违反任何服务条款。
商业智能的未来
机器学习和网络搜索应用程序接口(API)的前景一片光明。有了正确的工具和技术,这些技术将继续变得更强大、更易用。
使用机器学习和网络搜索可以在很多方面帮助企业,例如提高效率、节省时间和金钱,以及更容易获取有价值的数据。
但是,使用这些技术也会遇到一些挑战,比如确保数据的正确性和可靠性、处理隐私和安全问题,以及了解这些技术的复杂程度。
在使用机器学习和网络搜刮之前,必须仔细考虑这些问题,并确保正确使用收集到的数据。
使用代理服务器克服网络抓取难题
IPBurger 的旋转式住宅代理可让企业和组织轻松访问各种在线来源的数据,这些数据可用于机器学习和网络搜索。
Companies can ensure that the data sources they use are safe and reliable by using residential proxies that change over time. This lets them get the most out of their machine learning and web scraping projects.


