
歡迎來到機器學習和網頁抓取 API 的世界!隨著數位技術的興起,這兩個強大的工具在商業世界中變得越來越強大。
本文將探討機器學習和網頁抓取 API 的基礎知識,以及為什麼它們對企業很重要。因此,戴上您的思維帽,潛入數據驅動決策的美妙世界!
機器學習和網頁抓取 API 的定義
機器學習是一種人工智慧 (AI),它允許電腦無需顯式程式設計即可學習。它專注於開發可以訪問數據並使用它來自己學習的計算機程式。
因此,我們應該對電子產品更加友善。你知道,以防萬一。
網頁抓取是從網站中提取數據的過程。它涉及使用程式自動從網站獲取資訊並以結構化方式存儲。
網頁抓取 API 是應用程式程式設計介面 (API),允許開發人員以自動方式從網站中提取數據。這些 API 通常用於從網頁中提取結構化數據,並以更易於使用和操作的格式提供這些數據。網頁抓取 API 可以從各種基於 Web 的來源收集資訊,例如在線評論、新聞文章、社交媒體帖子和網頁。從網路抓取 API 收集的數據可用於許多應用程式,包括情緒分析、趨勢分析和個人化。
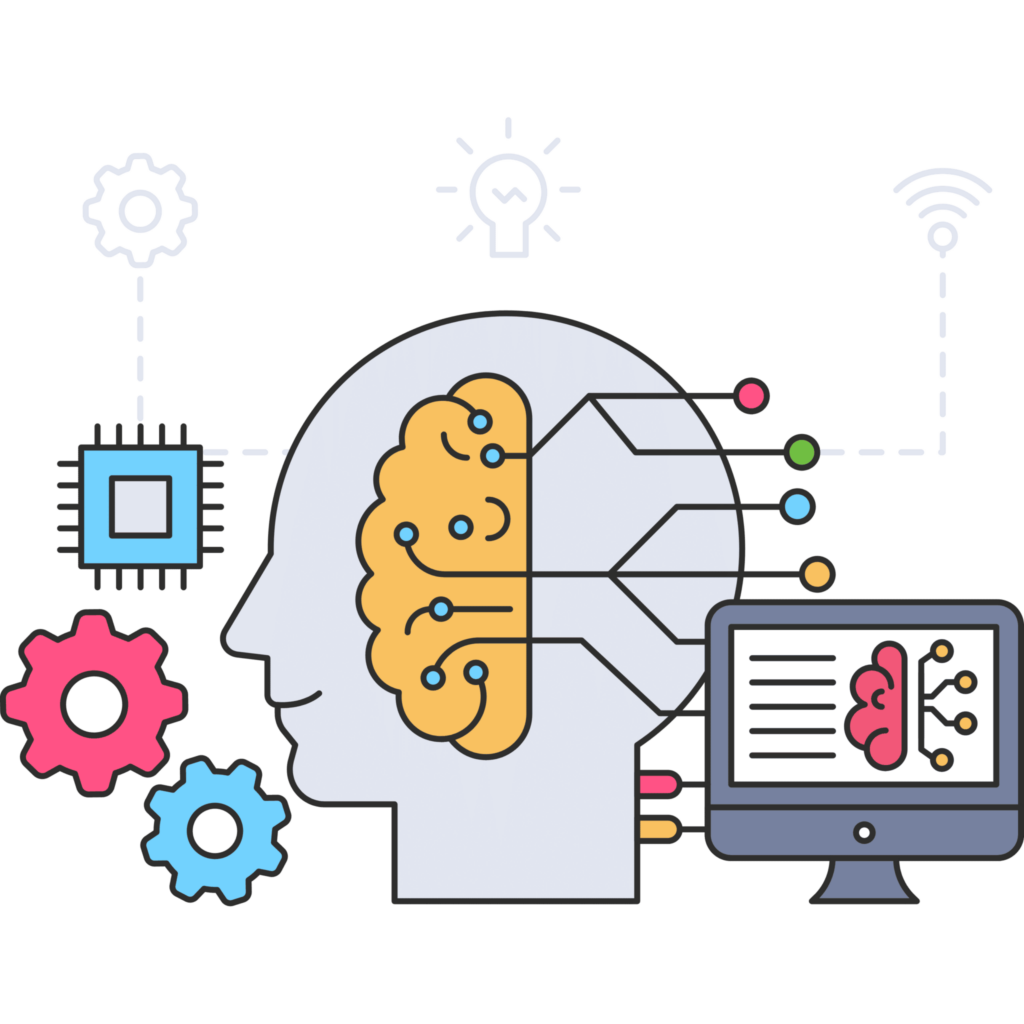
機器學習與網頁抓取 API 之間的關係
Web 抓取 API 可以從 Web 收集大量數據,然後可用於訓練有監督和無監督的機器學習演算法。
例如,網路爬蟲 API 可用於從網上的各種來源收集文字、圖片、音訊和影片,這些資料隨後可用於訓練自然語言處理(NLP)演算法。
網路抓取 API 還可以從社交媒體網站獲取資訊,以訓練分析人們感受的演算法。(祝你好運!
簡而言之,網路抓取使機器學習自動化,以便人工智慧可以自我通知。
利用機器學習和網頁抓取 API 的優勢
機器學習和網路抓取使收集和分析數據變得更加容易和快捷。
企業可以通過使用自動化演算法和流程來收集、組織和分析數據來節省時間和金錢。
機器學習和網路抓取還可以提高所收集數據的品質,因為它們可以從許多不同的來源找到並提取相關數據。
最後,機器學習和網路抓取使企業可以從各種來源獲取資訊。通過能夠訪問來自各種來源的數據,企業可以深入瞭解各種市場和行業,從而做出更明智的決策。
讓我們仔細看看機器學習和網頁抓取 API 的優勢:
- 降低成本: 自動網頁抓取比手動收集數據更具成本效益。
- 改進決策: 機器學習演算法可以幫助根據收集的數據做出更好的決策。
- 自動個人化: 機器學習演算法可以幫助根據過去的行為個人化用戶體驗。
- 改進的分析: 機器學習演算法可以説明查找無法手動找到的數據趨勢和模式。
- 提高準確性和效率: 網頁抓取 API 可以使用機器學習演算法更快、更準確地從網站獲取數據。然後,這些資訊可用於製作可以預測未來的模型,分析客戶數據,甚至自動執行比較價格等任務。
- 自動數據收集: 網頁抓取 API 可用於自動收集數據
- 更好的安全性: 網頁抓取 API 可以使用機器學習演算法在網頁上查找惡意內容。這有助於保護企業免受安全威脅。
- 更好的資料分析: 網頁抓取 API 可以幫助企業使用機器學習演算法來更好地分析他們的數據。這為他們提供了更深入的見解。這可以幫助企業做出更好的決策、優化運營並保持競爭力。
如何利用機器學習和網頁抓取 API
步驟 1:確定所需數據
要使用機器學習和網路抓取,第一步是找到您想要的數據。在此步驟中,您將定義機器學習演算法使用的數據並選擇資料的來源。
步驟 2:收集和清理數據
在弄清楚需要哪些數據后,下一步是收集和清理它。清理數據可能涉及執行簡單操作,例如消除重複項或將其放入機器學習演算法可以使用的格式。
步驟 3:設置機器學習演算法
收集和準備數據后,就該設置將用於處理和分析數據的機器學習演算法了。這將需要選擇正確的演算法並對其進行設置,以便它與數據一起工作並提供所需的結果。
設置演算法后,對其進行測試並確保其正常工作非常重要。這可以通過運行小型測試並評估結果來完成。如果發現任何問題,應在進行全面分析之前進行處理和修復。
一旦演算法正常工作,就可以使用它來處理和分析收集的數據。根據您想要發生的事情,您可能需要採取額外的步驟以有意義的方式解釋和呈現結果。
步驟 4:實現機器學習演算法
- 選擇適當的 ML 演算法。 不同的演算法可能會更好地工作,具體取決於任務的難度和您擁有的數據量。選擇演算法時,請考慮準確性、速度、可擴展性和可解釋性等因素。
- 收集和準備訓練數據。 這可能涉及清理、規範化、轉換和標記數據。
- 訓練模型。 這意味著將訓練數據放入模型中並調整參數以獲得最佳結果。
- 測試模型。 檢查模型在以前尚未看到的數據上的運行情況,並確保它足夠準確。
- 部署模型。 將模型集成到應用程式中,並在實際方案中監視其性能。
- 監視模型。 監控模型的性能並查找退化或漂移的跡象。根據需要重新訓練或調整參數。
利用機器學習和網頁抓取 API 的挑戰

實施成本
實施機器學習和網路抓取的成本可能相當高。根據專案的範圍和所需的資源,成本可以從幾百到數萬不等。此外,該系統需要由具有適當技能和培訓的人員製作和維護。這會進一步增加實施成本。

技術挑戰
利用機器學習和網路抓取存在一些技術挑戰。其中包括收集和準備數據、設計特徵、選擇和訓練模型以及使用模型。
此外,需要製作演算法,以便可以快速處理大型數據集,並且可以發現並修復數據洩漏、過度擬合和偏差等問題。

隱私和安全問題
機器學習和網路抓取的最大問題之一是它們可能會導致隱私和安全問題。當有人抓取網站時,他們可以獲取敏感的個人資訊,如姓名、位址和財務資訊。此資訊可用於找出某人是誰。此外,壞人可以使用機器學習演算法來獲取信用卡號和密碼等私人資訊。
準確性和可靠性
在使用機器學習和網路抓取時,確保收集的數據準確且可信也很重要。網頁抓取時可能會發生錯誤,因為收集的數據可能需要完成或可能是錯誤的。此外,機器學習演算法可能會犯錯誤,因為用於訓練它們的數據可能會給他們帶來偏見。因此,確保用於網頁抓取和機器學習的數據和演算法是好的非常重要。

法規遵從性
最後,重要的是要從法律和監管的角度來看考慮使用機器學習和網路抓取意味著什麼。在收集和使用數據時,組織必須確保它們符合相關的數據保護法律,例如GDPR和CCPA。
此外,組織還必須確保他們不違反任何服務條款。
商業智能的未來
機器學習和網頁抓取 API 的未來是吉祥的。有了正確的工具和技術,這些技術將繼續變得更加強大和易於使用。
使用機器學習和網路抓取可以通過多種方式幫助企業,例如提高效率、節省時間和金錢以及讓他們更容易訪問有價值的數據。
但是使用這些技術會帶來一些挑戰,例如確保數據正確可靠,處理隱私和安全問題,以及了解技術的複雜性。
在使用機器學習和網路抓取之前,請務必仔細考慮這些問題並確保正確使用收集的數據。
使用代理克服網頁抓取挑戰
IPBurger的 輪換住宅代理 使企業和組織能夠輕鬆訪問來自各種在線來源的數據,這些數據可用於機器學習和網路抓取。
企業可透過使用隨時間變動的住宅代理伺服器,確保其使用的資料來源安全可靠。這使他們能夠充分發揮機器學習與網頁爬取專案的效益。


